
A fundamental challenge for the reliability of distributed systems is the ability to observe and understand dependencies among components. The blindness from not understanding service dependencies is costly:
- Frustrating Root-cause Analysis: “The service looks fine; some otherdependency is causing errors.”
- Prolonged Outages: “Which service is causing the downtime?”
- Bad Deployments: “We didn’t know this code change impacts that service!”
- Ineffective Planning: “Which services are critical for end-user transactions?”
A new category of products is emerging to address the observability challenges across services. These observability products generate live maps and traces which capture the dependency structure among services. Additionally, they capture the golden signals of monitoring service health — latency, throughput and error rates. In this post, we discuss Netsil Maps and OpenTracing for delivering complete visibility into the dependency structure and health of service interactions.
Netsil Maps
The Netsil Application Operations Center (AOC) delivers auto-discovered maps of Kubernetes services and their interactions. The Netsil maps can be created at multiple abstraction levels of Kubernetes clusters. For example, the picture below shows maps at (a) host, (b) namespace, and (c ) pod level.
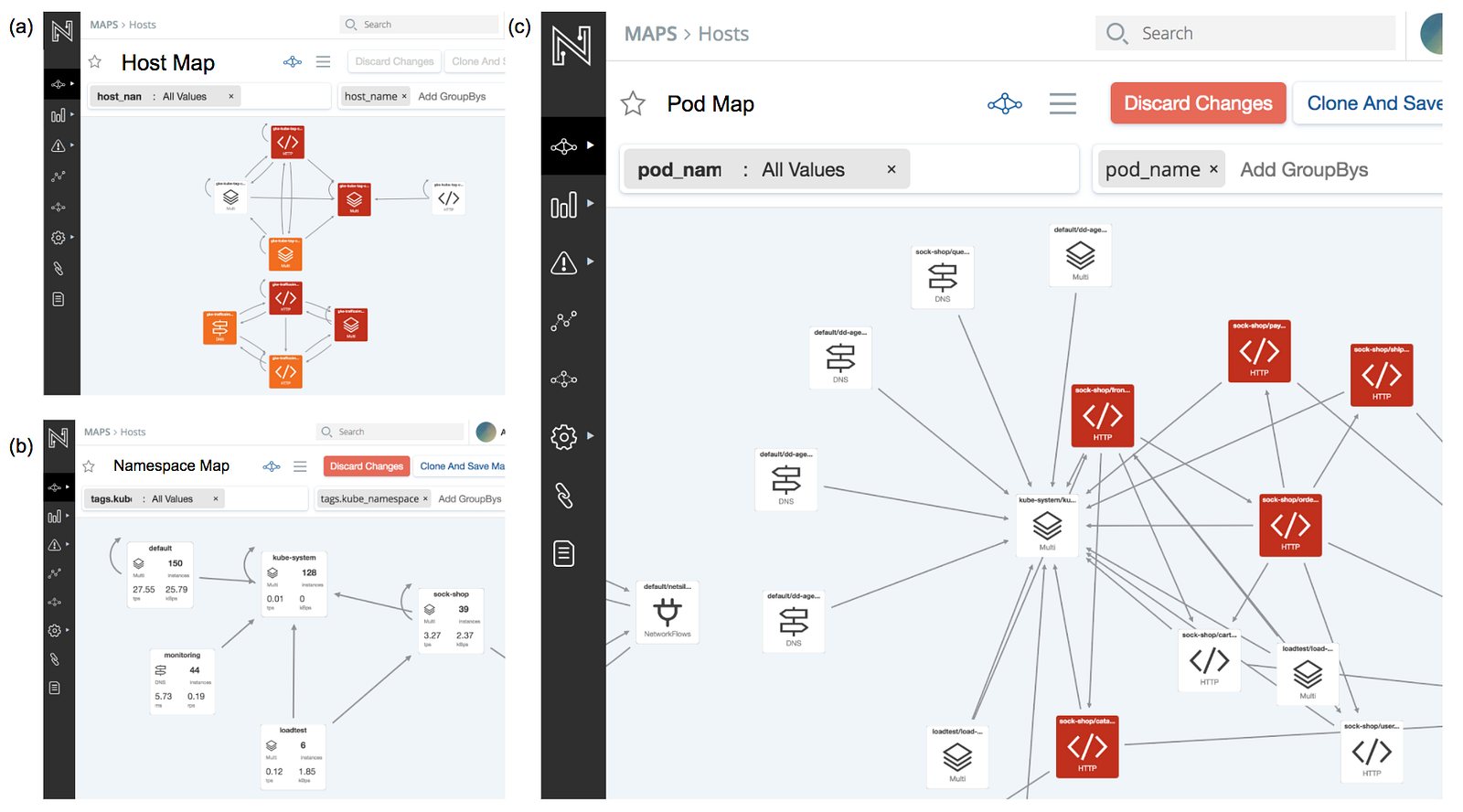
Along with the dependency structure, the Netsil maps also show the latency and throughput of service interactions. Deeper insights into any service interaction can be obtained by simply clicking on the link between the two services. For example, the picture below captures the complete profile of http interaction between the sock-shop/frontend and sock-shop/catalogue pods. The latency, throughput and error rates are presented grouped by insightful information on URIs, request methods, return status codes, etc.
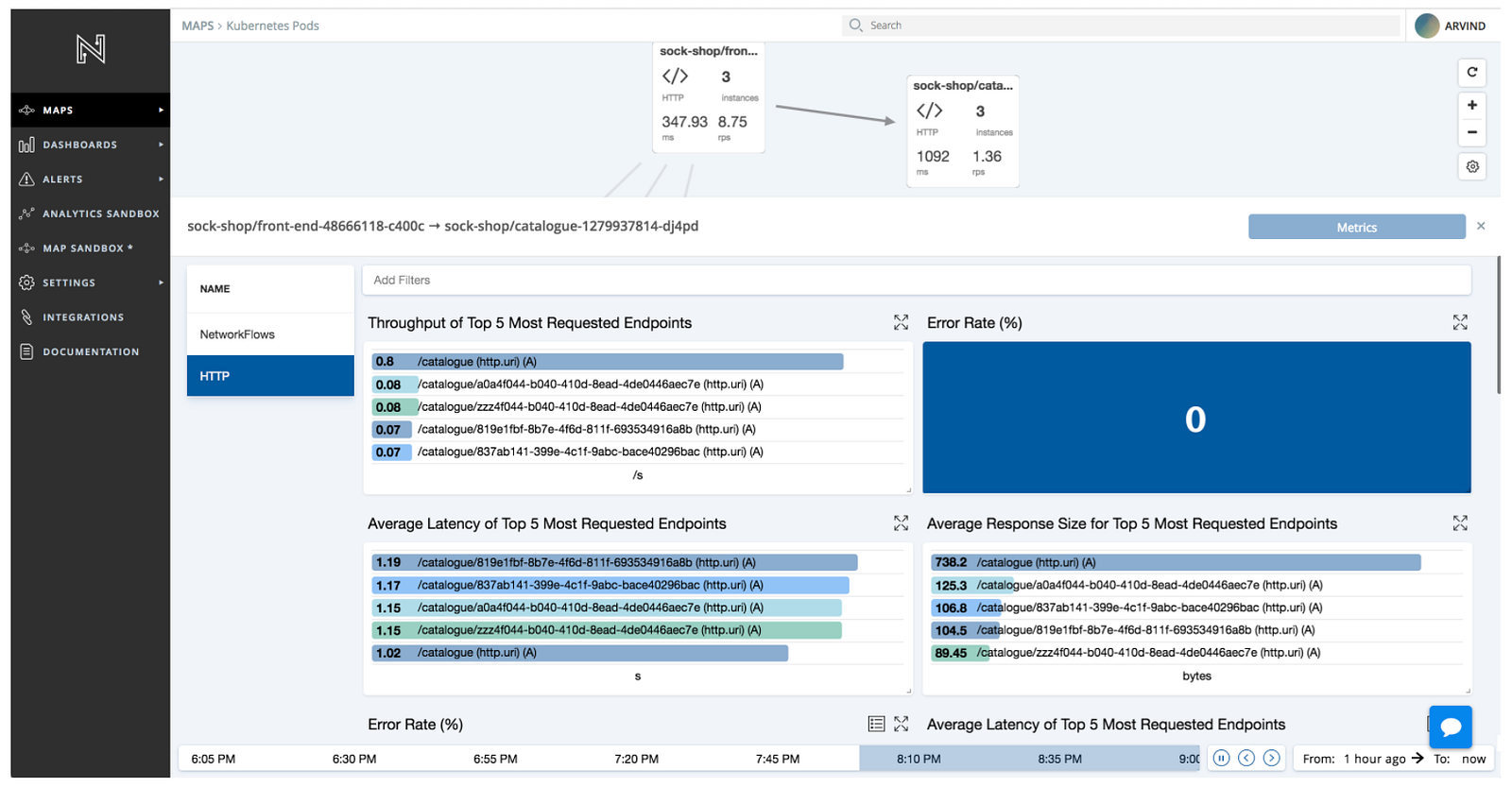
The Netsil AOC generates service interaction map by performing deep analysis of packets. As a result, Netsil maps don’t require any code change or container image changes to deliver complete visibility into the health of service interactions. The AOC has the capability to analyze and understand most of the common service protocols including gRPC, HTTP2, HTTP, PostgreSQL, MySQL, DNS, Cassandra, Redis, and many more (full list here).
The DevOps teams can easily deploy the Netsil collectors as DaemonSets and leverage the maps and metrics. One common use case of the maps is for deployment management. Every deployment has a significant risk of negative impact on other dependent services. The Netsil maps not only show you the dependency but can also alert you the negative impacts of latency increase, throughput drop or increase in error rates. This way you can prevent bad deployments from hitting production and avoid costly downtime.
The Netsil maps capture individual segments of services interactions. One limitation is that the causality information is lacking. The timestamps and call signatures i.e URI, MySQL query, etc. provide heuristics to deduce causality. Since the communications are highly repetitive, causality may not be needed at individual transaction-level. Nevertheless, if granular individual transaction level tracing is crucial for your debugging needs then OpenTracing is a good but laborious option.
OpenTracing
While Netsil employs a “black-box” approach to generating maps, OpenTracing employs what can be called a “white-box” approach. For OpenTracing (or distributed tracing in general), the application code:
- creates spans
- creates and send the required context to subsequent calls for linking spans
- establishes the causal link among spans.
For e.g. in the picture belows lets say A, B, C, etc. represent the services associated with the respective spans. Service A creates SpanA as part of its request processing. Only service A knows that it is calling Service B and C as a part of fulfilling the ongoing request. So service A will need to create the required context and send it to Service B and C, which can then link their respective spans as child of SpanA.
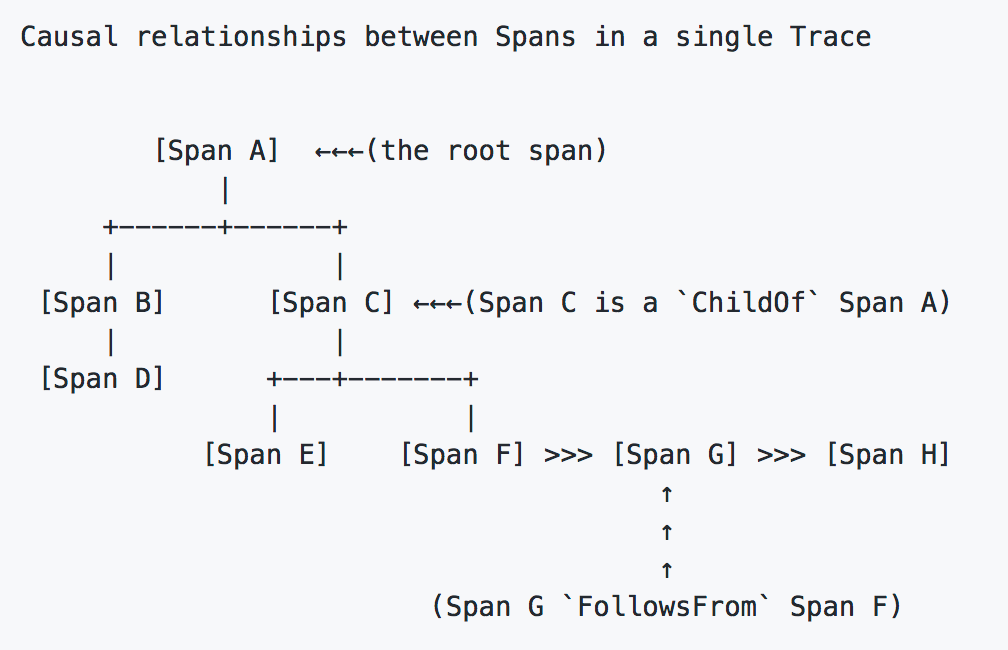
(credit: OpenTracing Specification)
It is safe to say that only the application has full context available to reliably establish the causality. So for all practical purposes, in order for tracing to work, you have to add tracing code to the application. This is pretty laborious undertaking especially considering the vast amount of code that is already written, which would be extremely hard to change just for inserting traces. Additionally, there are a lot of third party softwares such as cache, databases, payment processing, inventory management, etc. for which it might be impossible to insert tracing code. Every service that doesn’t handle the tracing will become a blind spot and termination point for the trace. Ironically, the seminal Google Dapper paper, which has inspired the many distributed tracing efforts, already warned of the brittle nature of relying on code changes for distributed tracing:
“Application-level transparency: programmers should not need to be aware of the tracing system. A tracing infrastructure that relies on active collaboration from application-level developers in order to function becomes extremely fragile, and is often broken due to instrumentation bugs or omissions, therefore violating the ubiquity requirement. This is especially important in a fast-paced development environment such as ours.” — Google Dapper Paper
Another important challenge with tracing is in terms of underlying protocols and required “room” for the propagation of the span context. While protocols such as HTTP provide support for custom headers, there are a lot of protocols which don’t have any room for passing additional context in headers. Modern communication channels such as gRPC, Thrift,etc. all have good support for OpenTracing but in the absence of these channels, the constraints of underlying carrier protocol become a challenge for propagating context across services.
Conclusion
Observing and monitoring service dependencies is critical for reliability and performance of microservices applications (and in general for any distributed application). With Netsil you get maps without any hard work and you get to understand the structure of the communications and transaction flows. Netsil maps and metrics can greatly help the DevOps teams with deployment management, incident response, root-cause analysis and capacity planning.
If transaction level granularity is required then you should consider a disciplined approach to adopting and instrumenting tracing across all the services. With tracing the burden is on the development teams to properly handle traces, ensure the underlying communication protocols can carry the context for traces and that there is scalable analytics available to query vast amounts of traces for meaningful insights. While tracing efforts might take months to bear fruit, you can deliver observability in minutes using Netsil for your kubernetes clusters.
Good To Read
Google Dapper Paper (At Google, the “uniformity” in the use of thread libraries, common RPCframeworks, etc. were key instrumentation points for adding tracing without requiring every app-dev team to add traces.)
Performance Debugging for Distributed Systems of Black Boxes (A seminal paper from 2003 describing the heuristics that can be used for understanding distributed systems without code-changes.)