

Previously we covered importing a Calm Blueprint into your own environment, modifying the necessary fields to customize it, and then deploying a fully functional Nutanix Cloud Native application with Nutanix Calm. Today we’re diving into the architecture of the blueprint.
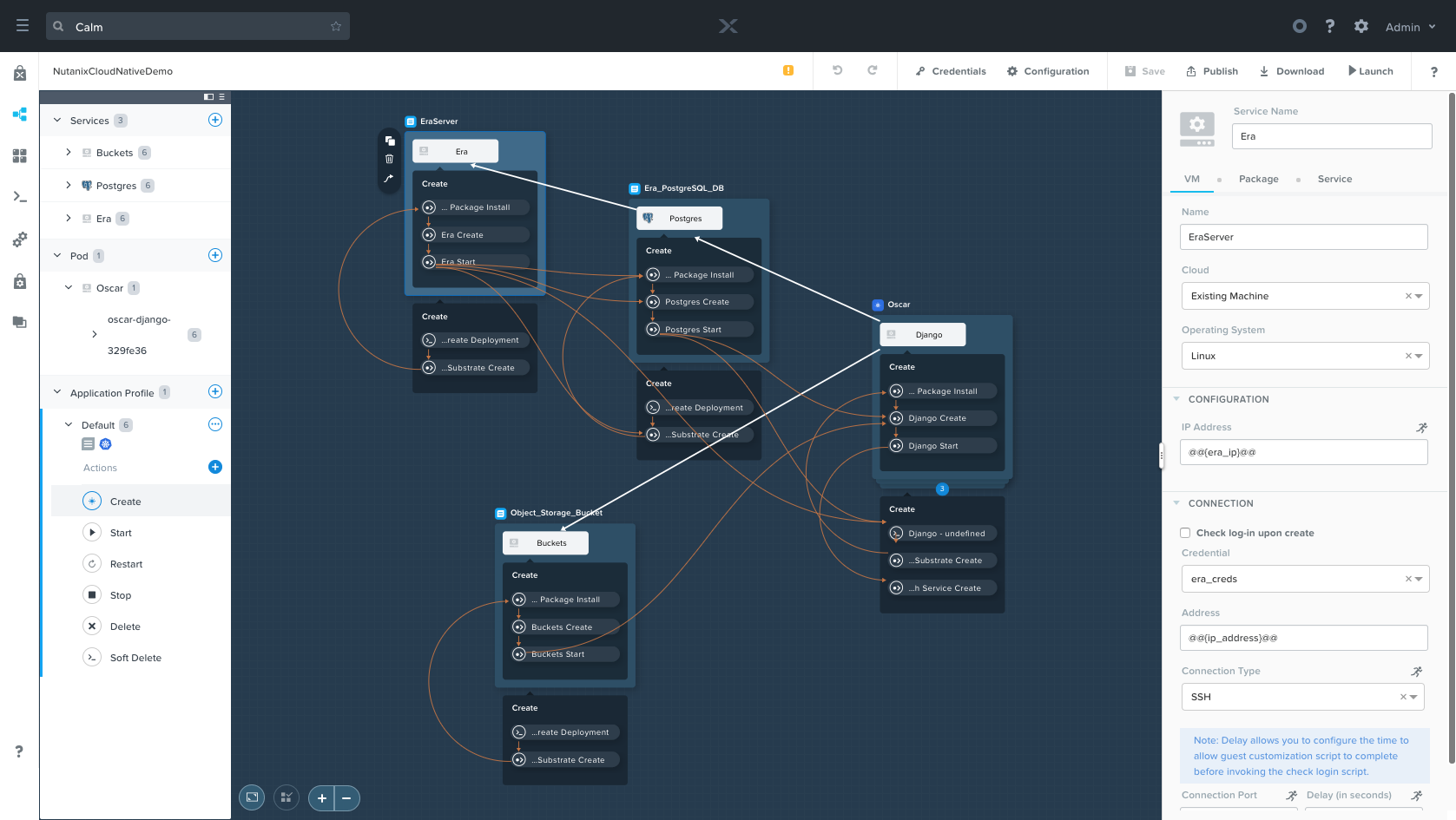
Era
Nutanix Era is a database management solution that that automates the provisioning and protection of Postgres, MySQL, Oracle, and other databases. Within our Calm blueprint, we’re adding our Era Server as an existing machine, with its IP tied to the era_ip variable covered in the previous post. Note that the “Check log-in upon create” button is unselected, as we do not actually need to SSH in to this VM, only perform Rest API calls against it.
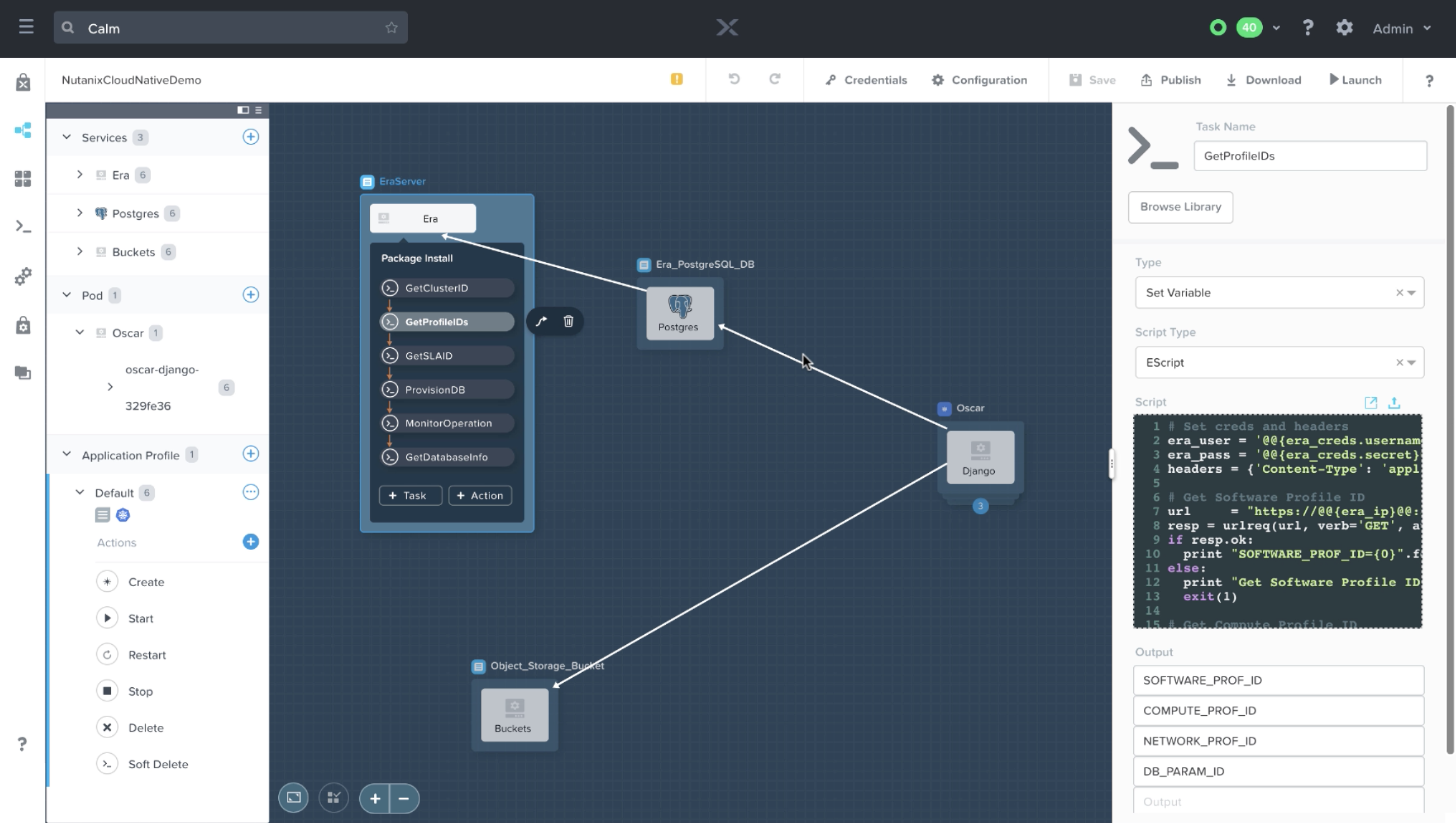
Navigating to the Package Install section, we see 6 different tasks, all of which are eScript. If you’re not familiar with how eScript works, please check out our Portal documentation, or this Calm in Action demo video. Each eScript task will be making one or more Rest API calls against the Era server, all with the end goal of deploying a fully functional PosgreSQL database:
- GetClusterID: this sets the CLUSTER_ID variable to the Prism Element cluster UUID that’s registered to our Era Server.
- GetProfileIDs: this task makes 4 different API calls to the Era Server, each one getting the UUID of the specific profile specified earlier in the variable section.
- GetSLAID: this task sets 2 variables, one of which is the database name (which is used in the next task) based off of the db_name_prefix we set in the variable section, and the second which is the UUID of the SLA, also based off of the name we set in the variable section.
- ProvisionDB: this task uses all the values previously gathered to provision our Postgres database, and then sets the resulting operation UUID to a variable, allowing us to monitor its progress.
- MonitorOperation: every minute, this task will call the Era Server to get the progress of the database provisioning operation, and once complete, it will set the database entity name to a variable.
- GetDatabaseInfo: this task sets various UUID and IP information about the database to variables, which are used later in the blueprint.
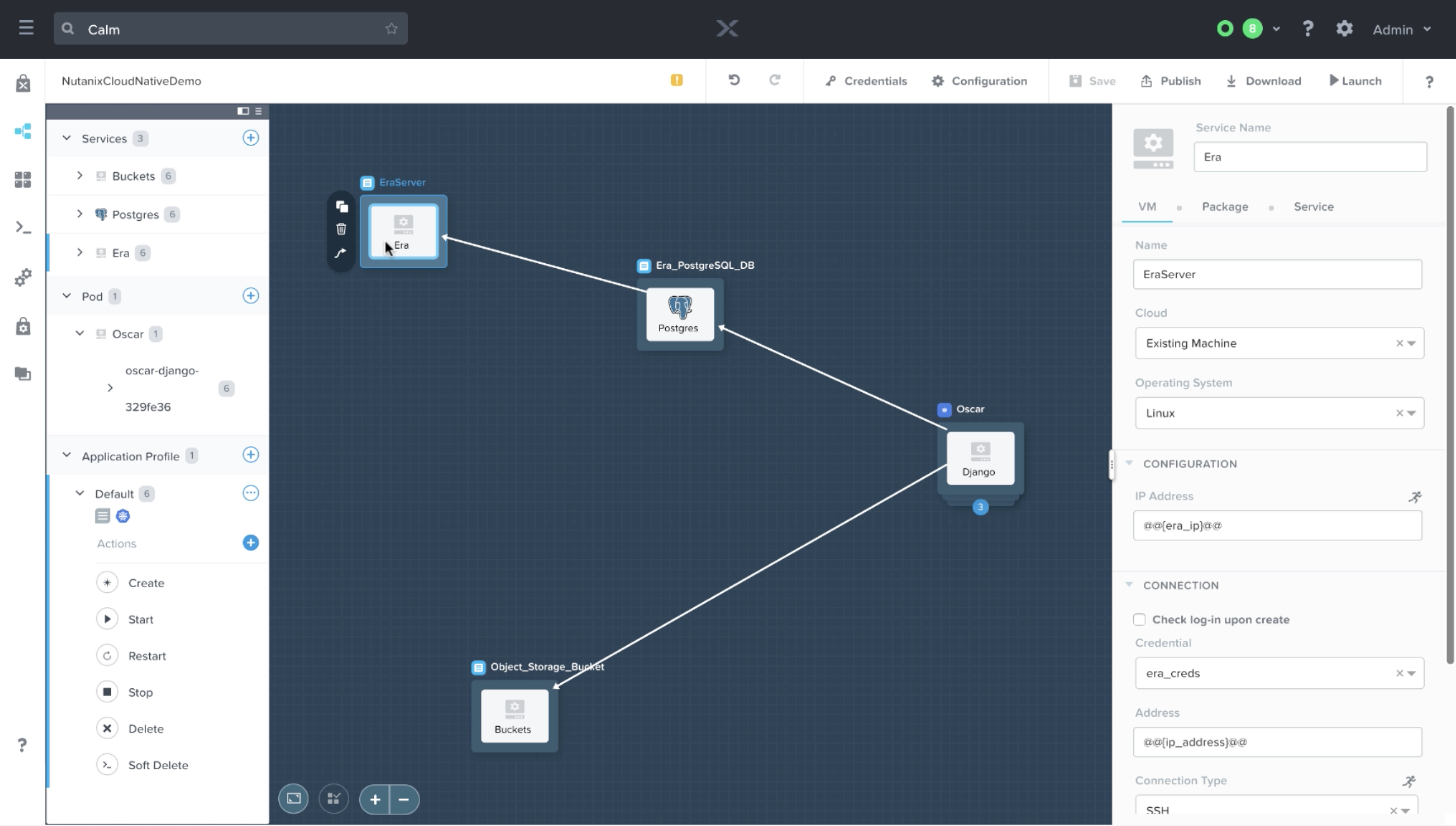
Postgres
Since our Postgres database is getting directly provisioned by Era rather than Calm, we’re specifying the Postgres database server as an existing machine. Take note of the macro specified in the IP Address section, we’re specifying a variable set during the very last task (GetDatabaseInfo) of the Era Service, which instructs Calm to build an orchestration edge (the line that the mouse is hovering over):
For the check login, we are leaving that toggle selected, as we want Calm to ensure that we can log in (via SSH keys) to our newly provisioned database. If we cannot log in, then we want the application deployment to fail before moving on to the next steps. For the package install, we only have a single task:
- CreateMigration: this task is calling the Karbon Kubernetes cluster API to create the Job that we mentioned in the credentials section. This Job seeds our newly provisioned database and object storage bucket with data, so our e-commerce application contains products at launch.
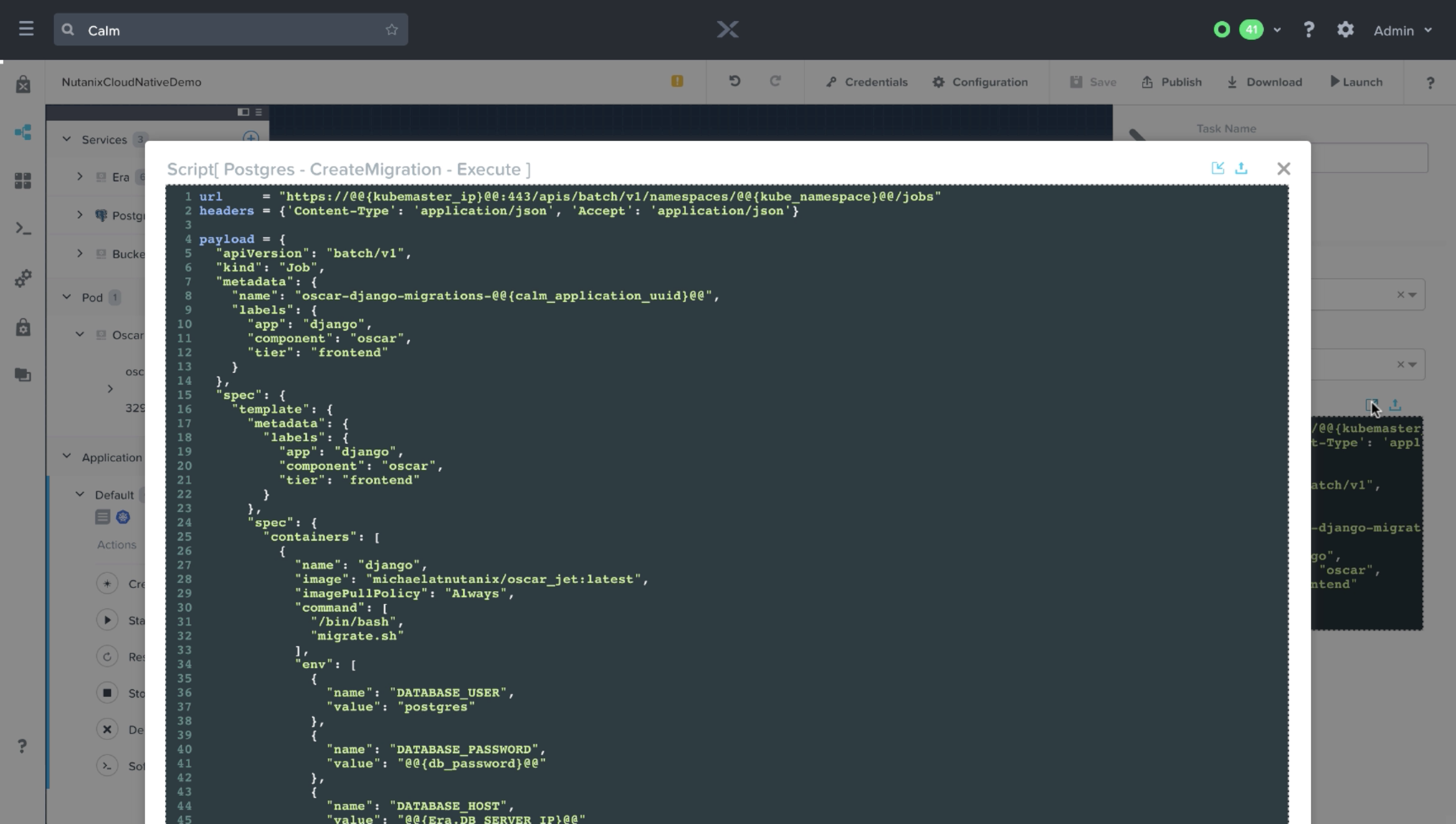
Buckets
Nutanix Buckets is an S3 compatible object storage solution. We’re also configuring our Buckets Service as an existing machine, as the Buckets Endpoint already exists. Since all buckets configuration is done via the Kubernetes Job and Deployment rather than Calm directly, we’re deselecting the check log-in box.
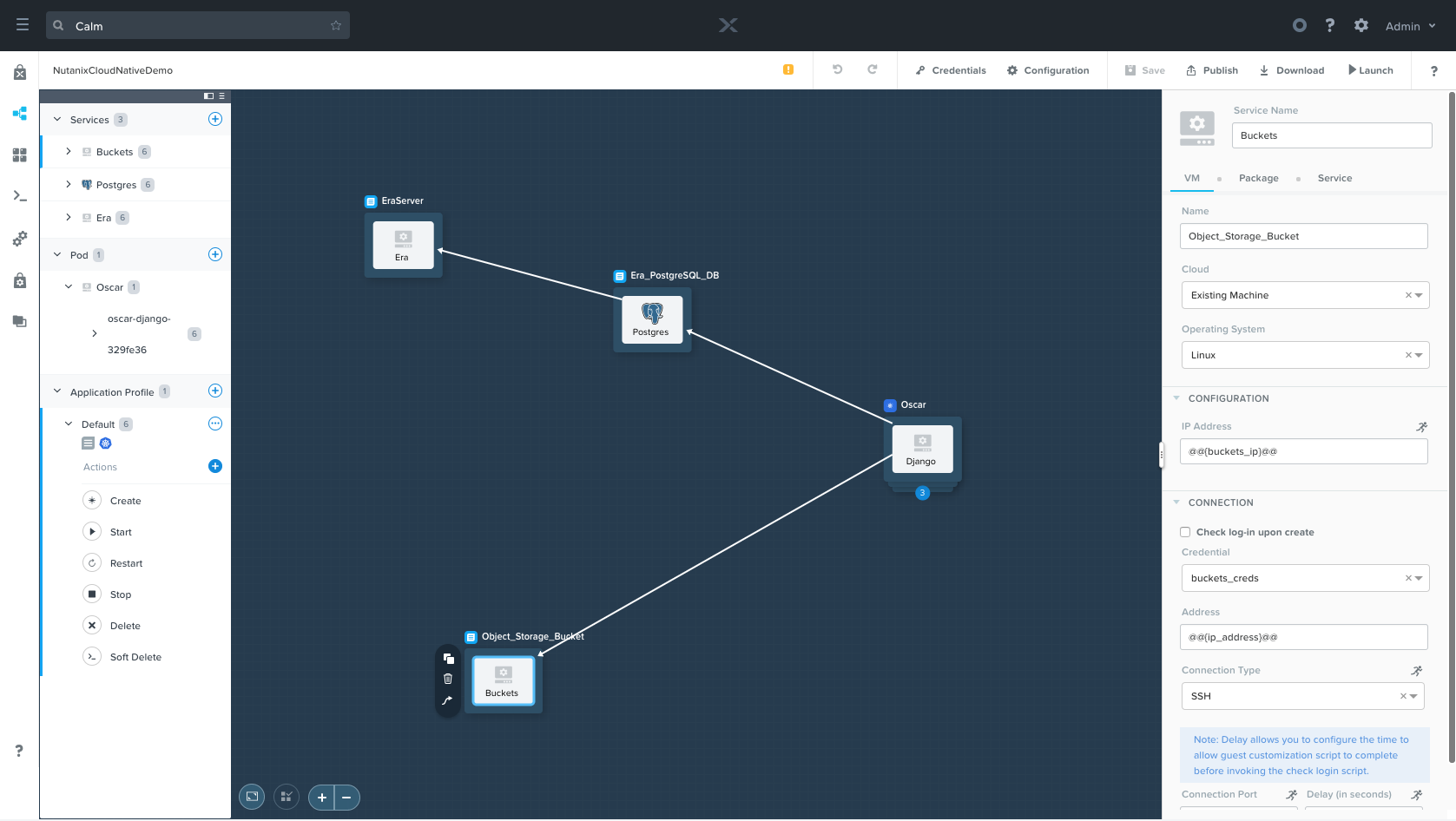
Oscar
Nutanix Karbon is an enterprise-grade Kubernetes distribution that simplifies the provisioning, operations and lifecycle management of Kubernetes. In the previous blog post, we showed adding an existing Karbon Kubernetes cluster as a provider to allow Calm to deploy Kubernetes objects.
In our blueprint, the Oscar Pod within Calm is composed of 3 different Kubernetes objects: a deployment, the containers, and a service. These objects correspond to the django yaml files described in the first Nutanix Cloud Native blog post. The key difference with the Calm blueprint is that the various database and bucket settings are not hard coded, rather they’re applied at runtime via our variables.
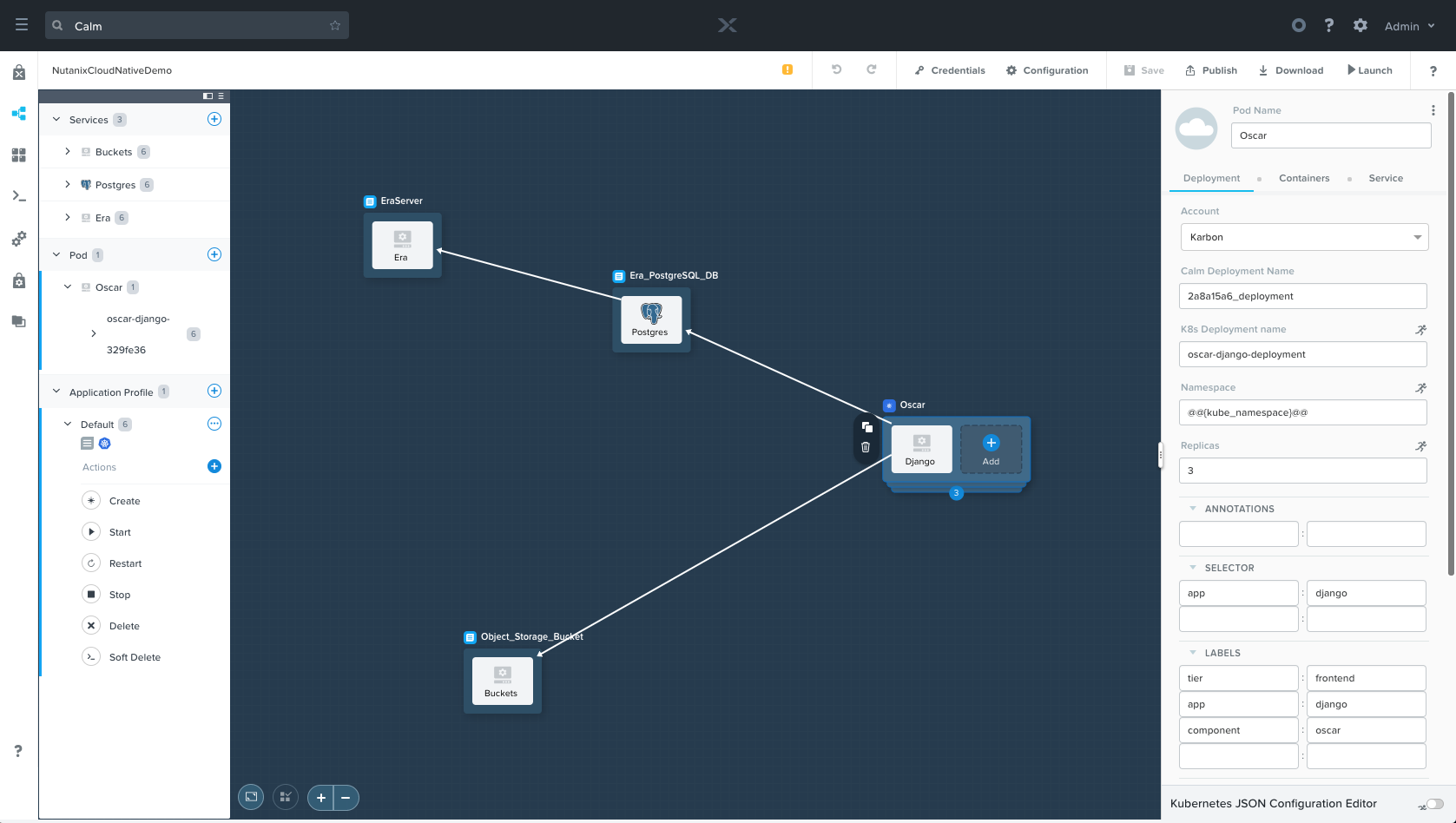
For each item, toggle the “Kubernetes JSON Configuration Editor” on and off to see how the various fields map to one another.
- Deployment: specifies the number of replicas, selector, metadata, and namespace.
- Containers: specifies the container image, ports, and various environment variables that tie into our Calm variables.
- Service: specifies the selector, metadata, namespace, and how we can access our pods (NodePort on port 8000).
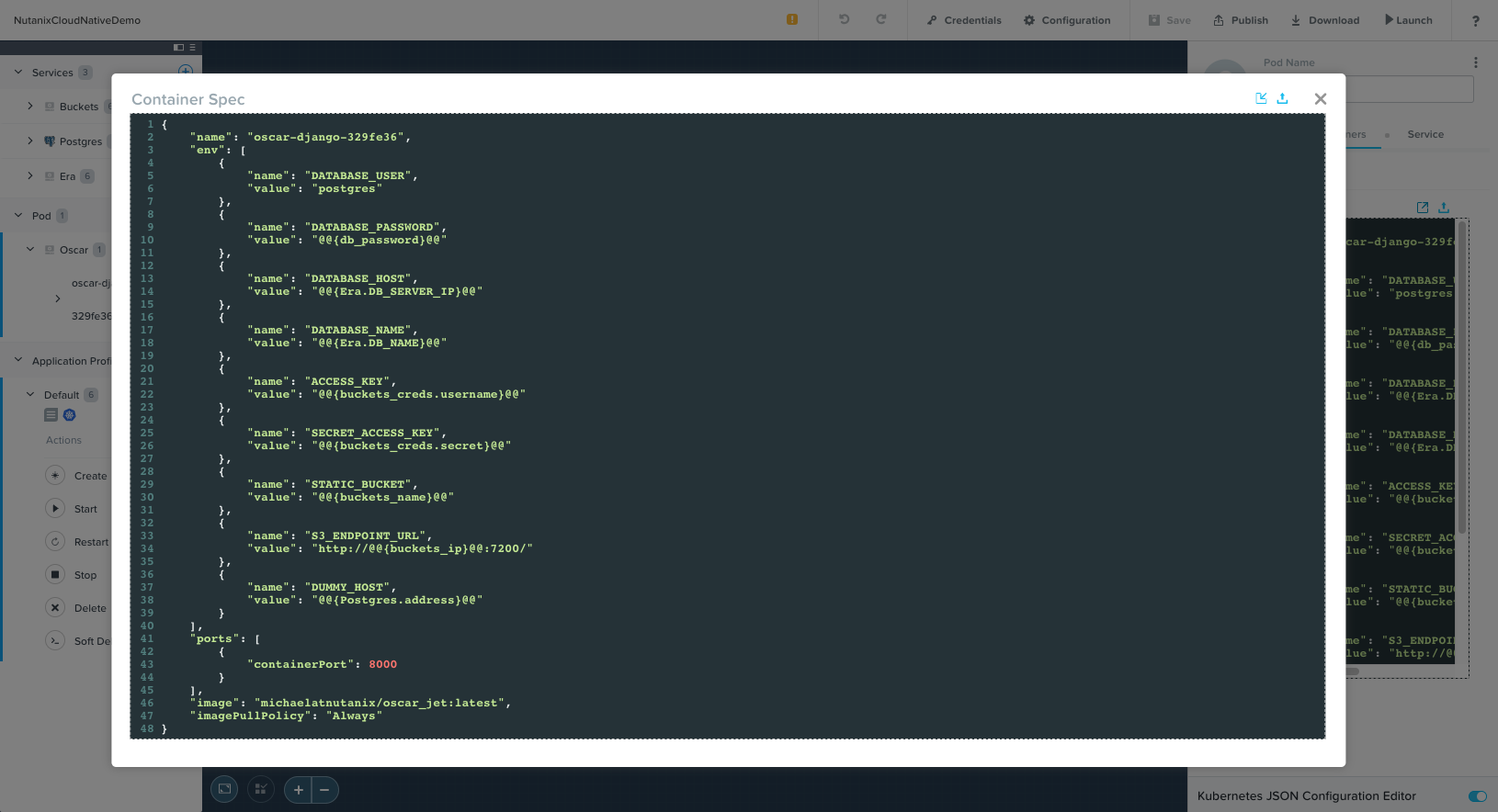
When this blueprint is launched, the variables will be subbed out for their runtime values, and Calm will call the Kubernetes API to instantiate these objects.
Stay tuned for our next post in this series where we’ll tie in Jenkins to create a CI/CD pipeline!