

You might be wondering – why is the featured image for this article a violin? Primarily it’s because the violin is a cool image (lol) but also because it’s a really nice, abstract way of looking at orchestration in detail. Ok, so that was bad – with that out of the way, let’s jump into today’s subject – Deploying Kubernetes clusters with the new Nutanix Karbon API.
This article is reasonably long, so grab your favourite beverage, sit back and see how the Karbon APIs can be used to deploy Kubernetes clusters
May 2021 – Note about VM specs
The original version of this article, published in July 2020, configured all virtualised components of the deployed Kubernetes demo cluster with 1x vCPU.
Nutanix Karbon 2.2 (released April 28th 2021), will not allow cluster deployments configured this way. To ensure the demo payloads below still function, the cluster specification has been altered to match the defaults used in the Karbon UI.
Quick Karbon Intro
The Nutanix Karbon homepage describes Karbon as follows:
Fast-track your way to production-ready cloud native infrastructure with Karbon, an enterprise Kubernetes management solution. Dramatically simplify provisioning, operations, and lifecycle management.
– https://www.nutanix.com/products/karbon
What does that mean for us as developers? Kubernetes itself is such an enormous topic on its own that going into detail about Kubernetes is beyond the scope of this particular article. That said, Kubernetes (or K8s), can be a fairly daunting prospect for new players. This can include things like understanding why K8s exists in the first place, what the requirements are and how to get a K8s cluster up and running. Karbon dramatically simplifies what can be quite a complex process, especially if that process is completed manually.
Like the developers that decided to refer to Kubernetes as K8s, I’m going to be lazy and assume you’ve got a script or third-party integration that needs to programmatically deploy a K8s cluster. To be clear, we are deploying a K8s cluster but we’re going to use Nutanix Karbon to do it. Even easier!
Karbon APIs
The Nutanix Karbon APIs were made generally available (GA) in July 2020. Those of you with an interest in the Nutanix APIs will have noticed a new resource on the API Reference page – this gives quick access to the Karbon API documentation. Everything covered in today’s article is available in official form there, including other API endpoints not covered here.
GA vs alpha/beta
As you go through the various endpoints that are exposed by the Karbon APIs, you’ll see various endpoint prefixes:
- /karbon/v1
- /karbon/v1-alpha.1
- /karbon/v1-beta.1
As the prefixes suggest, some of the available endpoints are Generally Available (GA) and are prefixed with /karbon/v1, whereas other endpoints are still considered alpha or beta and are prefixed with /karbon/v1-beta.1 or /karbon/v1-alpha.1. Appropriate caution should be taken before using the alpha or beta API endpoints in a production environment.
It’s worth noting that the main APIs endpoint we’ll use today are prefixed with /karbon/v1 and are considered GA. There’s a single exception to that, but I’ll mention it at the appropriate time.
Test Environment
As with all my API testing and development, I’m using Postman collections to organise my requests. If you are new to Postman, please consider reading the article titled “So many variables! How I test Nutanix APIs with Postman“. It covers how I use Postman to do exactly what we’ll be doing today.
Versions
Here are the software versions I’m using on my development cluster [updated May 2021]:
- AOS 5.20
- Prism Central pc.2021.3.0.2
- Karbon 2.2
- Nutanix Karbon OS image ntnx-1.0, indicated by {{karbon_image_version}}
Assumptions
Karbon does have prerequisites, so here are some high-level assumptions I’m making. These are for anyone following this article in their own environment.
- Your environment meets the requirements and has Karbon enabled. Please see the Requirements section of the Nutanix Karbon Guide for more information as this article won’t cover getting Karbon running in your environment.
- Nutanix Karbon OS image ntnx-1.0 has already been downloaded and is available for deployment. Please see Downloading Images the Nutanix Karbon Guide for more information.
List Existing Clusters
Before creating new clusters, let’s take a quick look at seeing what clusters may already be running in our environment.
The request URI for this is as follows (this is the single request in today’s article that is accessed via a beta endpoint):
https://[prism_central_ip_address]:9440/karbon/v1-beta.1/k8s/clustersBy sending this GET request to Prism Central, the JSON response will contain details on existing K8s clusters that are being managed by Karbon, if any exist. This request, when run against my test environment shows there are three existing K8s clusters being managed by Karbon. The entire response is quite long – please note the screenshot below only shows the first cluster in the response.

As you can see in the screenshot above, we now have details about the visible cluster’s etcd configuration, the API server’s IP address, the type of control plane deployment. Outside the screenshot we also have information about the workers, the Kubernetes version and various other parts of the cluster configuration.
Building the API Requests
Since we are going to deploy Kubernetes clusters using Karbon and the Karbon APIs, we can now get started on building out the request. To get started, here is the request URI we’ll be using to deploy K8s clusters using Karbon:
https://[prism_central_ip_address]:9440/karbon/v1/k8s/clustersThis is a POST request and therefore requires a corresponding JSON payload that tells the Karbon APIs what we actually want to do. As a small point of interest, let’s look at what happens if we submit a request to that URI without any JSON payload at all:
{
"code": 602,
"message": "body in body is required"
}As you can see, we are politely told that a JSON body is missing and is required before we can go any further. Along the way, you’ll see similar messages if you accidentally omit a required parameter or field within the payload. It’s not overly relevant but I often interchange the words “payload” and “body” when talking about HTTP POST requests. In the context of these articles, they’re the same thing.
Single Control Plane Kubernetes Cluster
(This will be referred to as a “development cluster” for the rest of this article.)
If you have some exposure to Kubernetes already, you’ll be aware that the Control Plane Node configuration can have a single control plane (for development) or or multi control plane (in large or production environments). This is an oversimplification, but single control plane clusters essentially match the “Development” deployment in Nutanix Karbon. A development cluster will be made up of the following components:
- 1x Control Plane node
- 1x Worker nodes
- 1x etcd node
Please see Kubernetes Components for information about the various Kubernetes components.
For this initial deployment, it’s important to note this configuration is not considered highly available. Any one of the components virtual machines could fail, resulting in cluster unavailability.
Let’s first look at the JSON payload that can be used to deploy a development Kubernetes cluster managed by Nutanix Karbon.
{
"cni_config": {
"node_cidr_mask_size": 24,
"service_ipv4_cidr": "172.19.0.0/16",
"pod_ipv4_cidr": "172.20.0.0/16",
"flannel_config": {}
},
"etcd_config": {
"node_pools": [
{
"name": "etcd_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 1,
"ahv_config": {
"cpu": 4,
"disk_mib": 40960,
"memory_mib": 8192,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
},
"masters_config": {
"single_master_config": {},
"node_pools": [
{
"name": "master_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 1,
"ahv_config": {
"cpu": 2,
"disk_mib": 122880,
"memory_mib": 4096,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
},
"metadata": {
"api_version": "v1.0.0"
},
"name": "{{karbon_cluster_name}}",
"storage_class_config": {
"default_storage_class": true,
"name": "default-storageclass",
"volumes_config": {
"username": "{{username}}",
"password": "{{password}}",
"storage_container": "{{container_name}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}",
"file_system": "ext4",
"flash_mode": false
}
},
"version": "{{k8s_version}}",
"workers_config": {
"node_pools": [
{
"name": "worker_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 1,
"ahv_config": {
"cpu": 8,
"disk_mib": 122880,
"memory_mib": 8192,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
}
}There a lot of information in that JSON payload, so let’s check out the highlights of what it will do. Variables indicated by {{variable}} are the values that should be changed to match your requirements.
- Cluster named indicated by {{cluster_name}}
- Components (as mentioned previously)
- 1x Control Plane
- 1x Worker
- 1x etcd
- The nodes are configured as follows:
- 8x vCPU for workers, 2x vCPU for the control plane and 4x vCPU for etcd
- 122880 MiB storage for workers and control plane, 40960 MiB for etcd
- 8192 MiB vRAM for etcd and workers, 4194 MiB vRAM for the control plane
- Connected to the same VM network, indicated by {{subnet_uuid}}
- Deployed to the same Prism Element cluster, indicated by {{cluster_uuid}}
- Kubernetes version 1.19.8-0, indicated by {{k8s_version}}
- Nutanix Host OS version ntnx-1.0, indicated by {{karbon_image_version}}
- CIDR ranges
- Service: 172.19.0.0/16
- Pod: 172.20.0.0/16
- Storage class named default-storageclass
- ext4 filesystem
- Reclaim policy set to Delete
- Storage container indicated by {{container_name}}
- Karbon API version v1.0.0
Those that have gone through the deployment of a Kubernetes cluster using the Karbon UI will notice each parameter matches 1:1 with what you see in the Karbon UI. In other words, the options you select while using the Karbon UI have all been specified in the JSON payload, too.
Sending the request
Sending the request to Prism Central will return a JSON response similar to what is shown below – note this response shows values after the requires variables have been substituted for real cluster names, etc:
{
"cluster_name": "single01",
"cluster_uuid": "30efbfd8-5544-4a58-53c4-2545658cc981",
"task_uuid": "21da123c-8911-41e8-acef-7653cbdc2aaa"
}The cluster name as per the JSON payload is clearly visible, as is the UUID of our new cluster as well as the UUID of the task that was created to handle the process. For the purposes of this article we can ignore the task_uuid and cluster_uuid – the Karbon API can be used to get info about what’s currently happening. We’ll do that shortly.
Multi Control Plane Kubernetes Cluster
(This will be referred to as a “production cluster” for the rest of this article.)
The JSON payload for a production Kubernetes cluster is slightly different. In addition to the information specified in the development payload, we can also specify a few additional properties. In a production you’d be more likely to use something similar to this, with the various parameters tuned to provide a highly-available configuration.
- The external IPv4 address of the control plane cluster, if an active/passive configuration is being used (this is what will be demonstrated with this payload).
- The number of control plane instances. This is set to 1 in the development configuration but is set to 2 here.
- Note the single_master_config object has been removed from the payload – it doesn’t apply to production configurations.
Here’s what the complete JSON payload looks like:
{
"cni_config": {
"node_cidr_mask_size": 24,
"service_ipv4_cidr": "172.19.0.0/16",
"pod_ipv4_cidr": "172.20.0.0/16",
"flannel_config": {}
},
"etcd_config": {
"node_pools": [
{
"name": "etcd_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 1,
"ahv_config": {
"cpu": 4,
"disk_mib": 40960,
"memory_mib": 8192,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
},
"masters_config": {
"active_passive_config": {
"external_ipv4_address": "{{karbon_prod_cluster_ip}}"
},
"node_pools": [
{
"name": "master_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 2,
"ahv_config": {
"cpu": 2,
"disk_mib": 122880,
"memory_mib": 4096,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
},
"metadata": {
"api_version": "v1.0.0"
},
"name": "{{karbon_prod_cluster_name}}",
"storage_class_config": {
"default_storage_class": true,
"name": "default-storageclass",
"volumes_config": {
"username": "{{username}}",
"password": "{{password}}",
"storage_container": "{{container_name}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}",
"file_system": "ext4",
"flash_mode": false
}
},
"version": "{{k8s_version}}",
"workers_config": {
"node_pools": [
{
"name": "worker_pool",
"node_os_version": "{{karbon_image_version}}",
"num_instances": 1,
"ahv_config": {
"cpu": 8,
"disk_mib": 122880,
"memory_mib": 8192,
"network_uuid": "{{subnet_uuid}}",
"prism_element_cluster_uuid": "{{cluster_uuid}}"
}
}
]
}
}Sending the request
Because we’re using the same API endpoint that we used when creating the development, the response follows the same exact format to the response from the previous request – cluster_uuid, task_uuid and cluster_name.
Getting Cluster Information
With our cluster or clusters now running or still being deployed, it helps to be able to query them.
The Karbon APIs also expose an endpoint for getting information about a specific cluster. This is a GET request and must be made to the following URI:
https://[prism_central_ip_address]:9440/karbon/v1/k8s/clusters/[k8s_cluster_name]For this part we’ll use the name of our production cluster – multi01. Replacing [k8s_cluster_name] above with the name of our cluster will return a response similar to the one shown below:
{
"cni_config": {
"flannel_config": null,
"node_cidr_mask_size": 24,
"pod_ipv4_cidr": "172.20.0.0/16",
"service_ipv4_cidr": "172.19.0.0/16"
},
"etcd_config": {
"node_pools": [
"etcd_pool"
]
},
"kubeapi_server_ipv4_address": "10.42.250.49",
"master_config": {
"deployment_type": "multi-master-active-passive",
"node_pools": [
"master_pool"
]
},
"name": "may2021-prod",
"status": "kActive",
"uuid": "2fb1c877-856d-4557-67c1-4a6ca2c36706",
"version": "1.19.8-0",
"worker_config": {
"node_pools": [
"worker_pool"
]
}
}There’s quite a lot of useful information shown here:
- The Kubernetes API server IP address as specified in our payload i.e. 10.42.250.49
- The deployment type i.e. multi-master-active-passive
- Most importantly for this section, the status i.e. kActive – this cluster has been successfully deployed and is ready to be used
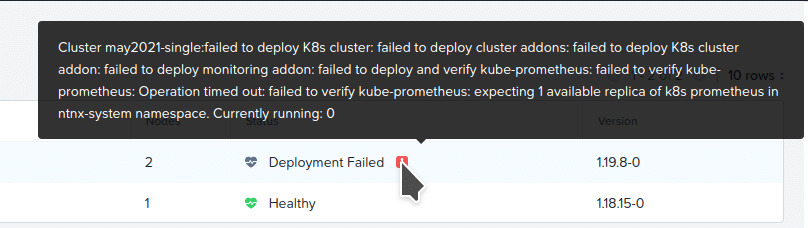
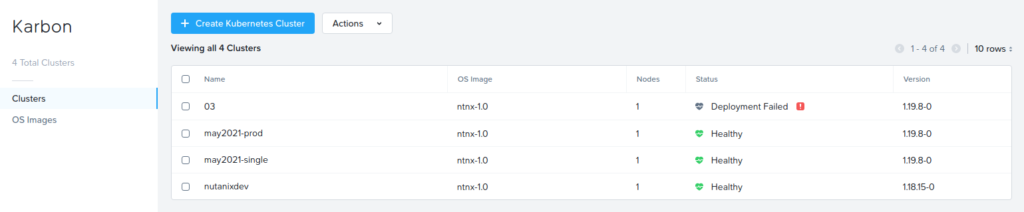
Once the deployments have completed, both will show as “Healthy” in the Karbon UI, just as they would if you had created them using the UI itself. Below we can see both the demo clusters from this article are deployed and healthy, along with another demo cluster and a failed deployment that was caused by a human error in the JSON payload.
Downloading Kubeconfig
The K8s clusters created using the Karbon API don’t differ at all from the K8s clusters created using the Karbon UI. For this reason, we can still download the Karbon-generated “kubeconfig” file. This file is used to run kubectl commands against the deployed K8s cluster. Please see Downloading The Kubeconfig in the Nutanix Karbon Guide for official documentation.
For what we’re doing today, though, the kubeconfig file can also be downloaded using the Karbon API. The GET request URI is as follows:
https://[prism_central_ip_address]:9440/karbon/v1/k8s/clusters/[cluster_name]/kubeconfigSending this request to Prism Central and substituting [cluster_name] with a valid cluster name will return a JSON response containing the kubeconfig. An example is shown below – the certificate authority data and token have been removed to make the example a little easier to read:
{
"kube_config": "# -*- mode: yaml; -*-\n# vim: syntax=yaml\n#\napiVersion: v1\nkind: Config\nclusters:\n- name: single01\n cluster:\n server: https://10.42.250.85:443\n certificate-authority-data: CERT_AUTHORITY_DATA_HERE\nusers:\n- name: default-user-single01\n user:\n token: TOKEN_HERE\ncontexts:\n- context:\n cluster: single01\n user: default-user-single01\n name: single01-context\ncurrent-context: single01-context\n\n"
}Wrapping Up
This article went into quite a lot of detail about the JSON payloads and Karbon API endpoints that can be used to programmatically deploy K8s clusters, as well as get information about clusters that are already managed by Karbon. While this is not a difficult process in terms of API concepts, the payloads themselves can take time to figure out at first.
Hopefully the examples above have demonstrated how you can integrate the Karbon APIs and K8s deployment automation into your own workflows.
Thanks for reading and have a great day! 🙂