

Here in the Developer Marketing team at Nutanix, we’re often tasked with creating scripts, demos and apps for the purposes of marketing both products and technologies. Outside of that “day to day” stuff, we’re very much an “eat your own dog food” team, that is, we use the same technologies to accomplish our own tasks as we do when writing that demo content.
In today’s article we’ll look at one of the ways we’ve done that recently. This particular use case is for a very large project that Mark Lavi, Principal DevOps Advocate, and I have been part of for some time. The requirement is to take submissions from people anywhere around the world, “test” their submission and make sure that certain criteria have been met.
Because the submissions are Nutanix Calm blueprints exported as JSON files, they’re in a format that is already very familiar to us. That means it is relatively easy to go through each one and see how the submission has been written and what the configuration is, with each “manual” check like this taking from 15-30 minutes depending on how much feedback is required.
However, what if we needed to evaluate the criteria of 1000 Nutanix Calm blueprints at a time? 15-30 minutes per manual check is a process wouldn’t scale very well at all. Let’s see how we automated that process.
Components
The components of the overall system are broken down as follows.
- Script. Python script that does the actual evaluation.
- Data. This is the exported Nutanix Calm blueprint that has been submitted for evaluation.
- Criteria. A JSON file that contains criteria against which the blueprint should be evaluated.
- Calm DSL. Used on request when valid blueprint verification is required. This isn’t part of making sure a blueprint is “correct”, only that the blueprint can be used by Calm.
- Evaluation blueprint. The Nutanix Calm application that brings all the above components together and forms the evaluation “system”.
Part 1 – Data
Because we are evaluating user submissions as JSON files that have been exported directly from Nutanix Calm, we can make a few informed assumptions.
- That the exported blueprints are provided as a single JSON file. This is how Nutanix Calm exports blueprints and makes the distribution of those blueprints extremely easy, any time.
- That the exported blueprints are valid JSON, “parse-able” using Python functions provided by the standard
jsonmodule. Regardless, a number of error-handling checks have been implemented so that we can gracefully fail if the JSON file isn’t valid for some reason. - That the exported blueprints will contain certain specific objects, lists of objects, certain data as Python dictionaries etc. This way we can look for specific parts of the blueprint and check their validity vs the criteria.
The screenshot below shows Nutanix Calm blueprint we’re using for evaluation testing. It is very simple, deploying a single VM that just gets Linux package updates and applies a basic firewall configuration.
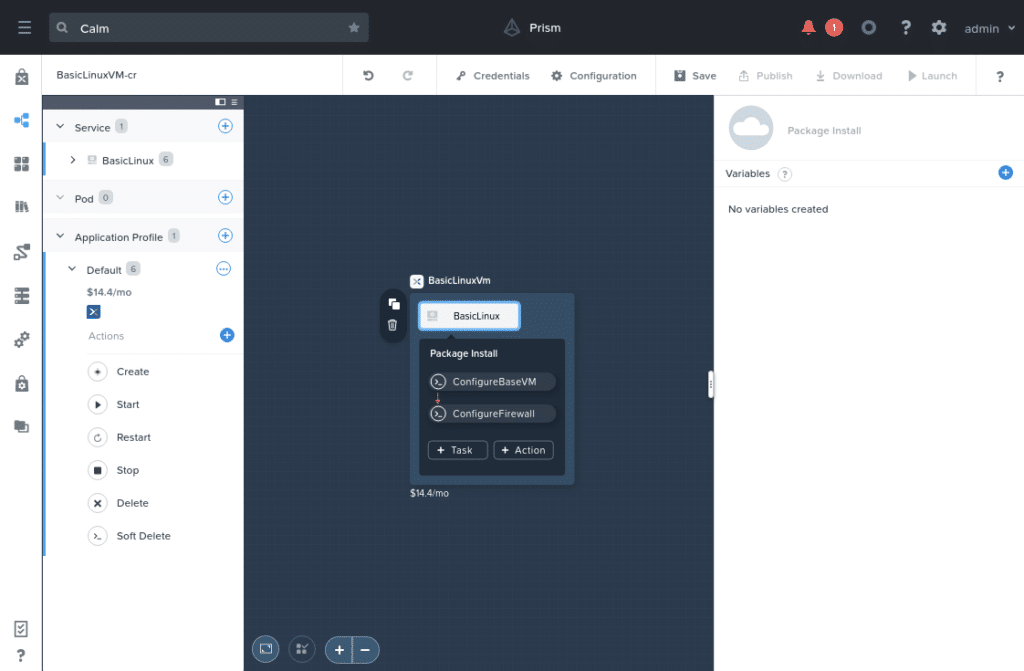
If you would like to download this blueprint to use during your own testing, you are welcome to do so via the Nutanix.dev Code Samples page.
Part 2 – Criteria
As part of this project, those people submitting blueprints have been asked to ensure their Nutanix Calm application meets certain criteria. Because of the way a Nutanix Calm blueprint is structured, we can easily check their submissions against that criteria.
From a programmatic perspective, there are many ways to achieve this. The evaluation script could contain the criteria, but that could make later updates potentially difficult by anyone that isn’t familiar with Python development. With this in mind, we decided to store the evaluation criteria in JSON files that relate to specific sets of requirements. The example is part of one of our JSON criteria files.
{
"criteria": [{
"description": "Entity Lists",
"type": "entity_lists",
"lists": [{
"key_desc": "Calm Service Instances",
"key": "spec.resources.service_definition_list",
"expected": 1
},
{
"key_desc": "Calm Package Instances",
"key": "spec.resources.package_definition_list",
"expected": 2
},
...
]
},
{
"description": "Application name",
"key": "spec.name",
"type": "string",
"match": "contains",
"expected": "BasicLinuxVM"
}
]
}As you can see, the criteria contains various key/value pairs and lists relating to what is being checked:
description– the name of the check, used for display and logging purposes.type– the type of check being carried out. The evaluation script will first check the value oftypeand then carry out the evaluation based on the value of that key.match– an example of the evaluation criteria itself. The contents of this field will vary based on the type of check. Amatchvalue ofcontains, as shown here, tells the evaluation script that the value found in the blueprint must contain the text found in theexpectedfield.expected– what we are expecting the contents of that field to be (i.e what is “correct” vs what is “incorrect”).
From the snippet above, let’s consider this specific section from the lists list:
{
"key_desc": "Calm Package Instances",
"key": "spec.resources.package_definition_list",
"expected": 2
}This check examines the blueprint and makes sure that the number of “Calm Package Instances” is exactly 2. From a terminology perspective, a Calm Package Instance covers application components such as Package Install scripts i.e. steps that are carried out as a VM is deployed.
Part 3 – Script
The script that carries out the actual evaluations is made up of several key components. Most of these are for versatility vs actual functionality, but I’ll go over them quickly anyway.
EnvironmentOptionsclass. A single instance of this class is instantiated at the start of the script and is used to hold environment-specific settings. These include the directory containing the blueprints, the criteria file being used for the current run (etc). This class exposes a public method calledcheck_environmentthat looks at the input already collected and returns True or False, depending on whether or not we have everything needed to complete the evaluation. More info on how we collect these settings will be covered shortly.EvaluationItemclass. Each time a criteria item is evaluated, an instance of this class is instantiated so we can “package” settings and results specific to that evaluation. For example, if we’re evaluating the name of the application, available inspec.namewithin the blueprint, the evaluation key (spec.name) and the expected vs found values will be stored in this class. Abstracting this information into a separate class like this isn’t functionally advantageous, but provides a modular style that could be considered good coding practice.Messagesclass. This class (which could easily be a<a rel="noreferrer noopener" href="https://docs.python.org/3.8/library/dataclasses.html" target="_blank">dataclass</a>), holds the various messages and formatting options that are used throughout a complete blueprint evaluation.
Part 4 – Calm Blueprint
The Calm Blueprint is the final but probably most important part of this overall system. It is actually a really simple blueprint, deploying a single CentOS 7 Linux VM. This VM is deployed in the following order:
- The VM itself is deployed using the publicly-available CentOS 7 cloud image (links directly to the .qcow2 image).
- 4 package install tasks are completed, as follows:
ConfigureBaseVM– installs Linux updates.InstallCalmDSL– installs the Nutanix Calm DSL, used for part of the blueprint verification step.InstallEval– gets the evaluation script, criteria files and test blueprints from our GitHub repositoriesTestEval– carries out a test to make sure the VM is ready for “real” evaluations
- The application is also deployed with a post-deployment action called
RunEval. This post-deployment action allows the user to run the same evaluation steps thatTestEvalcarries out, without needing to re-deploy the entire application. For example, if the user deploys the app then uploads a collection of blueprints to be evaluated, a new evaluation run can be completed without re-deploying the app. Simple, but repeatable – the way DevOps processes are supposed to be, right? 🙂
Those familiar with Nutanix Calm applications may find it easier to see the application as it looks in the Nutanix Calm blueprint designer:
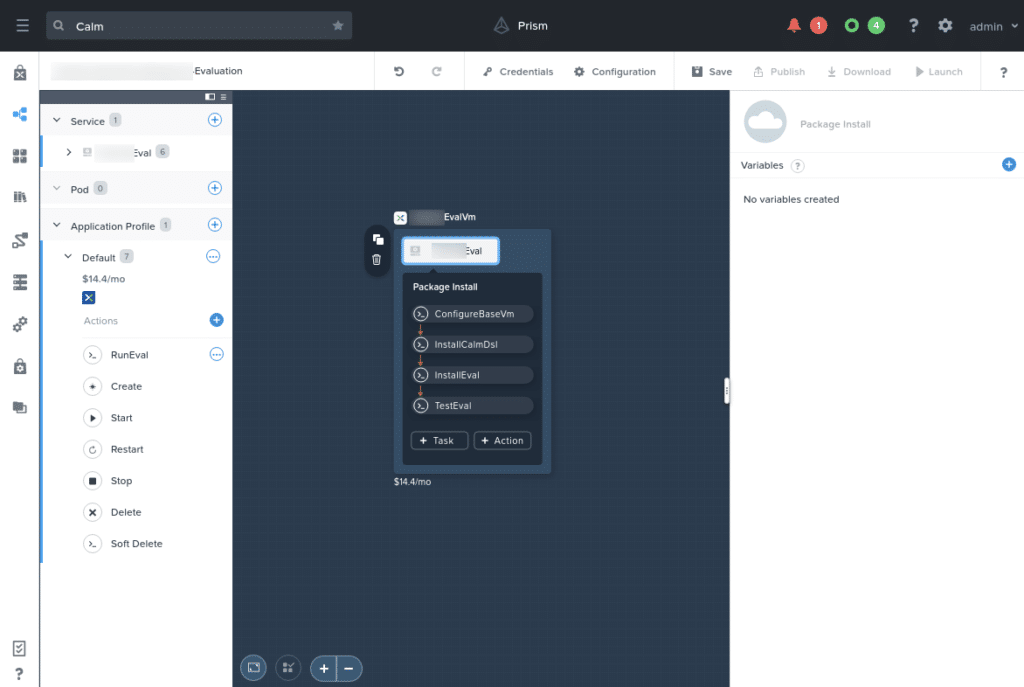
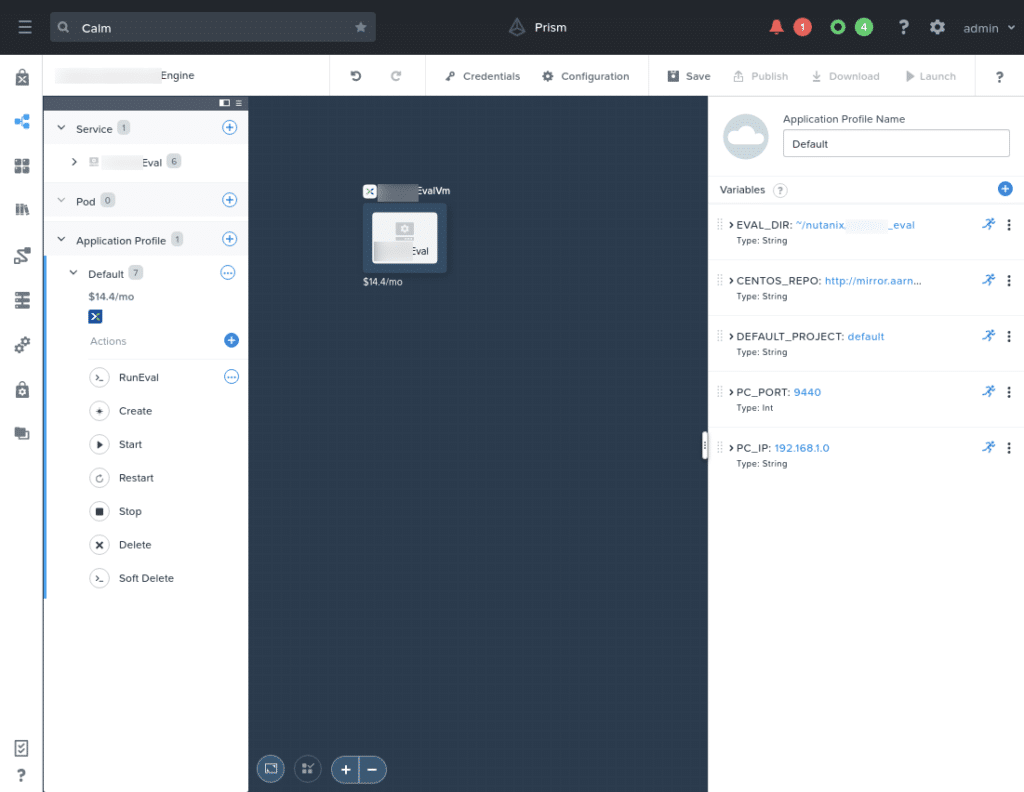
In addition to the package install tasks, a number of runtime application variables are made available. These variables allow the user to configure how the application will run in their environment. The variables are as follows:
EVAL_DIR– the directory that will be created to store the blueprints. In the example above, the user would upload new blueprints to this directory after the application is deployed.CENTOS_REPO– used during testing, this variable allows the user to specify which CentOS repository should be used as the main package source.DEFAULT_PROJECT– specifies which project the Calm DSL should use when verifying blueprints.PC_PORT– the port to use when connecting to Prism Central (should never need to be changed).PC_IP– the IP address of the Prism Central instance used by the Calm DSL. This instance must have an existing project matching the value ofDEFAULT_PROJECT.
User Parameters
In order for this system to work, we’ve provided a collection of command-line parameters. These parameters allow the user to script exactly how the evaluation should function, resulting in a system that can be easily automated or fit into another workflow of almost any sort. The script’s design has been intentionally done this way for a very simple reason – a script that prompts for input can’t be easily automated.
Available Parameters
The command-line parameters are shown in the screenshot below:
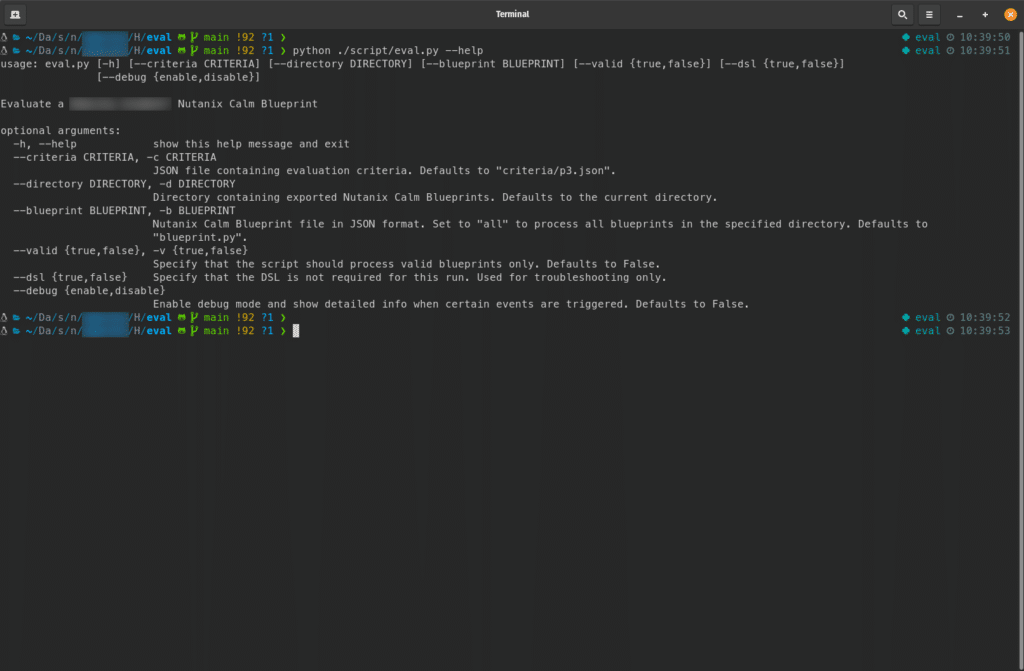
One thing you may note here is the --blueprint parameter. This parameter is used to specify which blueprint(s) will be evaluated, and can be passed three different ways.
- A single blueprint by filename
- No blueprint at all so that the script defaults to
blueprint.py all. Setting--blueprinttoallwill tell the script to process all JSON files in the directory specified by--directory. This is how we’re able to process as many blueprints as necessary, all with a single command.
Parameter Usage Example
For example, I have a directory containing 1024 blueprints. For the purposes of testing they are all the same application i.e. copies of the sample blueprint above. To process them all in a single run, the following command can be used.
python ./script/eval.py --criteria ./criteria/eval2.json --directory ./1024-blueprints --blueprint all --dsl false --debug enableThe time it takes to process a large collection of blueprints can vary depending on the number of criteria being evaluated and on the “size” of the application being evaluated, too. This is because each JSON file will take up a certain amount of system RAM as it is loaded and parsed.
As you can see, however, processing a large collection of small blueprints can be completed fairly quickly:
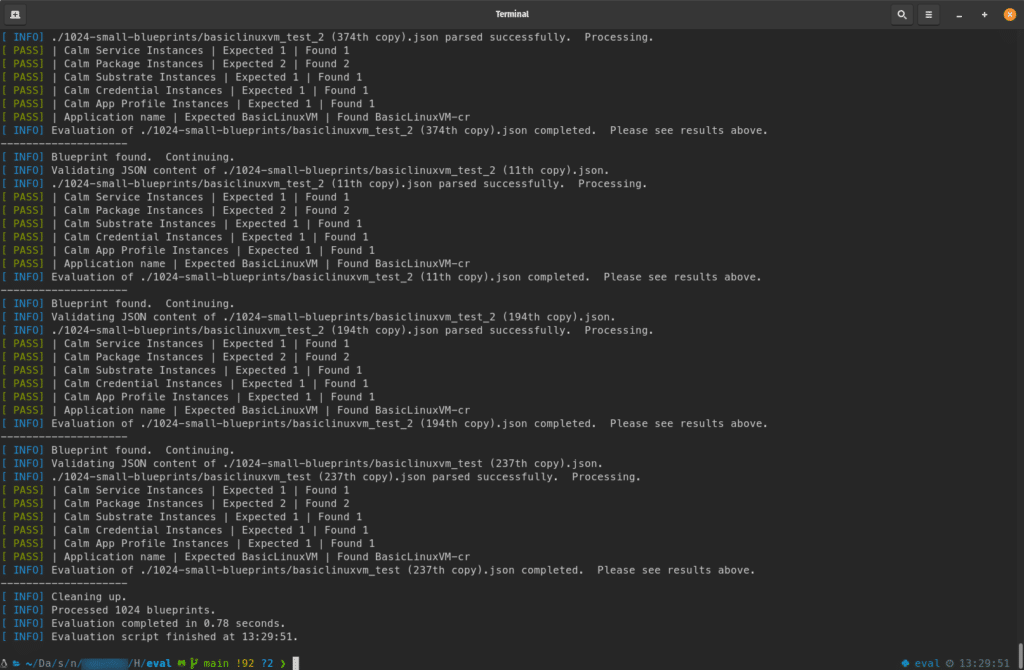
For comparison, 1024 production blueprints, submitted from real users, can be evaluated in 23.38 seconds. 🙂
It’s worth noting that the time to evaluate all the blueprints is with the --dsl parameter set to false. When setting the --dsl parameter to true, the script will login to Prism Central for every blueprint and use the Calm DSL decompile option to verify the blueprint is valid. The time taken for each DSL verification is dependent on a number of factors (e.g. network conditions), but is around 1-2 seconds per blueprint on my system.
Calm DSL Verification
Let’s take a quick look at how the script uses the Nutanix Calm DSL to verify the validity of each blueprint. Before diving into this, there are many resources available for those not familiar with Nutanix Calm DSL – please start at the Calm DSL home page for all the resources on Nutanix.dev, or at the Calm DSL GitHub Repository for the source code and official docs. If you would like to implement something in your own scripts, please see Introducing the Nutanix Calm DSL as it contains complete steps on getting the DSL ready for use in your own environment.
Before loading the evaluation criteria, each blueprint can be verified as a valid blueprint by using the Calm DSL. The benefits of doing this are two-fold.
- Needless evaluation is avoided.
- Any invalid JSON will be identified before it is evaluated.
Enabling Calm DSL blueprint verification is a case of using the --dsl parameter when running the script, as follows:
--dsl true|false where “true” instructs the script to verify all blueprints using the Calm DSL, before carrying out the evaluation.
The code that does this check is as follows. Note that by the time we get to this point, the script has already checked if calm is available in the user’s path.
# verify the blueprint is valid, if requested
if environment_options.dsl:
try:
# try to decompile the BP using the Calm DSL
result = subprocess.run(
[calm', 'decompile', 'bp', '--file', bp],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
if "Successfully decompiled." in str(result.stdout):
print(f'{messages.info} {bp} is a valid Calm '
+ 'blueprint. Continuing.')
else:
print(f'{messages.error} {bp} cannot be verified '
+ 'as a valid Calm blueprint. Skipping.')
exit
except FileNotFoundError as e:
print(f'{messages.error} Unable to execute the '
+ '\'calm\' command. Exiting.')
sys.exit()
else:
# calm DSL blueprint verification is disabled
print(f'{messages.info} Calm DSL blueprint verification '
+ 'disabled. Continuing.')All we’re doing here is executing the command calm decompile bp --file <blueprint.json> and parsing the results. A Python FileNotFound error will still be thrown if something has changed and means calm can’t be executed, but other than that a successful decompilation will return a message containing the phrase “Successfully decompiled.” That’s very easy to check for.
Putting Everything Together
The point of this entire exercise is to have a single, repeatable application that can be deployed and managed at any time via Nutanix Calm. As explained above, a single CentOS 7 Linux VM is deployed that contains the following key components:
- Evaluation script
- Data to be evaluated
- Criteria to use for the evaluation
By using the example commands also shown above but running via Calm blueprint package install tasks or post-deployment actions, we can maintain a lightweight environment capable of evaluating a large number of submissions in a very short time. Let’s see how an example deployment looks.
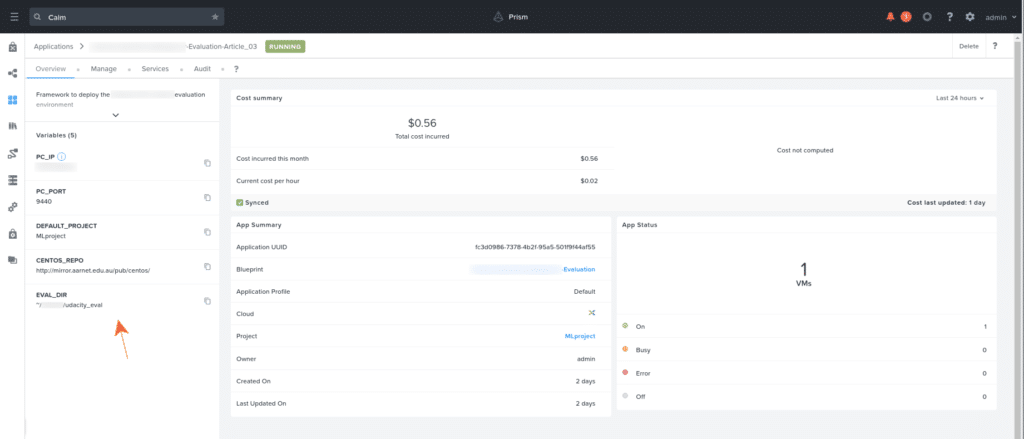
The user-specific settings, as outlined above, are indicated by the orange arrow.
Taking a deeper dive into the deployment itself, we can see the sequence that was followed to deploy the entire application (from the application Create step through to Start, i.e. when the application is running).
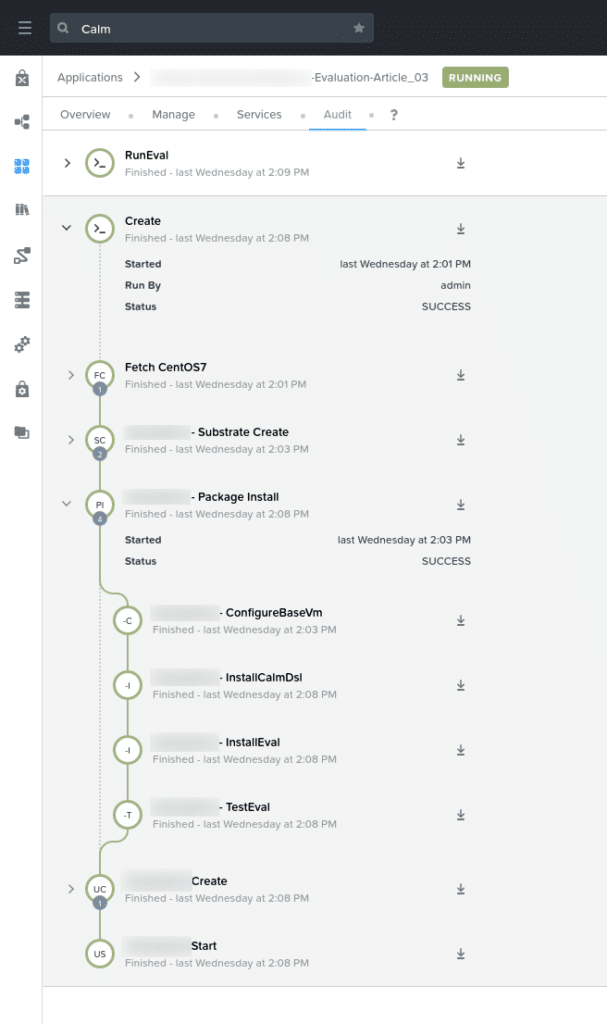
Lastly, we can see the example deployment above also shows a manual run of the RunEval task. This task runs the evaluation script as shown previously, evaluating the blueprints in order.
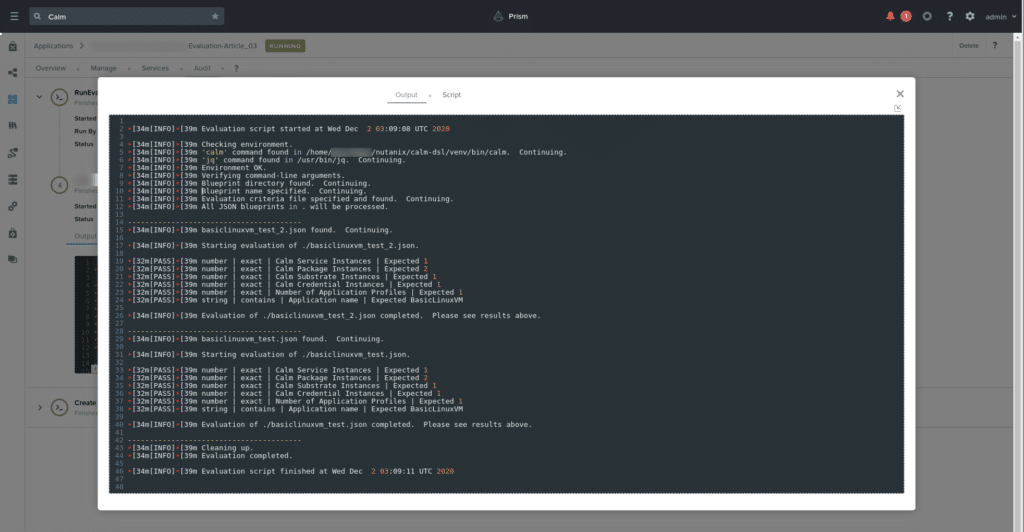
RunEval executionWrapping Up
Hopefully this reasonably detailed article has shown that Nutanix Calm isn’t only aimed at “standard” applications such as LAMP stacks, databases and other environments that provide a “normal” app function. We’ve shown that Calm can deploy anything that can be designed as an application including, as in this example, an app that evaluates blueprint submissions from our users.
The app is simple, the post-deployment actions are repeatable and the repetitive nature of these steps has been completely automated and removed. Cool.
Thanks for reading and have a great day. 🙂