

In today’s article I’m happy to introduce yet another guest writer! Everyone, please say a virtual hello to Raghav Tulshibagwale, Staff Engineer here at Nutanix. In today’s article, the first part of what will be an ongoing series, Raghav will take us on a journey of RocksDB at Nutanix and how it applies to various aspects of the Nutanix platform architecture.
There’s no way I can explain any of this better than Raghav himself, so let’s dive right in!
Introduction
Since an architecture review meeting in early 2016, Nutanix Engineering has been working on three major goals for our distributed storage fabric: improving sustained random write performance, adding support for large-capacity deep storage nodes, and making background data management more efficient.
As we articulated these goals and got into the details, we realized that our limiting factor was in the architecture itself. To improve further and anticipate future scalability needs, we would need to completely reimagine how we store metadata on Nutanix. Our primary objective — moving metadata closer to the data — required a new foundational component for storing metadata.
Introducing an entirely new component into a system that is already working well is a risky endeavor. We ultimately selected the open-source key-value store (KVS) RocksDB, but only after researching different options and weighing the potential costs and benefits of each. We wanted to make sure that an open-source solution would be sufficiently reliable and durable, and that our team could build enough expertise in just a few months to be able to truly own the component.
Our first post in this blog series presents some key terminology, the overall autonomous extent store (AES) project requirements, the selection criteria for the new component, an overview of the RocksDB deployment for the extent store, and a quick look at some other Nutanix products and components that now use RocksDB. Subsequent posts will review the challenges, successes, and lessons we’ve encountered with RocksDB so far and cover specific use cases in more detail.
Key Nutanix Terminology
Before we go into the details, let’s define some of the Nutanix terminology used in the course of our discussion.
The extent store is the persistent Nutanix data storage subsystem that manages user data in terms of extents hosted on disks. The extent store also handles other operations, such as data transformations, migration.
The metadata store is the distributed persistent storage layer that manages metadata for all user data stored by the extent store. The metadata store maintains two states: the global state, which provides information for cluster-wide properties, and local metadata (limited to a disk on a given host), which provides information about data layout on that disk. The Nutanix metadata store is a highly modified version of open source Cassandra, guaranteeing strong consistency and data durability. Internally, it uses a modified version of the Paxos consensus algorithm to service a distributed environment. You can find more information about the internals in the NSDI Metadata Store Paper.
The background data management system (BDM) in the Nutanix distributed storage fabric drives garbage collection, data transformation policies, data deduplication, data movement for tiering, and so on. It uses a modified MapReduce framework to make these intelligent decisions. You can find more information about the internals in the NSDI Curator Paper.
Requirements
Improve Sustained Random Write Performance
While working on a performance escalation for the databases backing a leading Electronic Health Record platform, we saw that the extent store was not driving the desired sustained random write performance because of high write amplification and the significant involvement of the metadata store in the I/O path. As the metadata store is a separate highly distributed service, I/O requires multiple host hops to complete a transaction under the Paxos protocol. Between jumping out of the I/O store service address space and crossing the network, Paxos consensus protocol complexities started to impact the overall user data write I/O path. Significant improvements to sustained random write performance became a top priority requirement.
Implement Support for Deep Storage Nodes
Given the falling prices of spindles and a proportional increase in their capacities, supporting deep storage nodes for use cases like object storage, long-term storage service, backups, and so on became an important priority. Our goal was to support at least 300 TB per node.
Reduce Cost of Background Data Management
The background data management system (BDM) uses the metadata store to make decisions based on reading and scanning the metadata. BDM performs global scans on the metadata store as part of the MapReduce framework, and these scans become very costly operations as the cluster sizes grow. Global deduplication comes with its cost: the metadata store must keep significantly more metadata to support the pattern extraction and matching operations it requires. Overall, the cost of “global” metadata management to support various use cases was increasing. To address this cost, we aspired to change the fundamentals behind all the BDM operations (data tiering, deduplication, etc.).
As we outlined the following requirements, it became increasingly clear to us that we would need to fundamentally change the architecture of the extent store.
New Extent Store Architecture
“Bring the metadata closer to the data” became the foundational principle for redesigning the existing extent store. In other words, make the extent store autonomous, so it can make decisions about local data using local metadata, instead of consulting the global distributed metadata. This change would enable individual nodes to host extent store data modifications, providing local background data management. We, therefore, had to bring the physical layout metadata from the metadata store much closer to the extent store.
To do this, we needed a database or KVS that could be deployed locally on a host where we could move all the physical data layout metadata (local state) from the metadata store. Given the increasing sizes of disks, each disk would become an autonomous storage system capable of handling its own data (extents) and the metadata for that data (extent layout information).
This local metadata storage required a new system. We had the following goals when we started researching a potential database or KVS:
- Should reside in the same address space as the extent store service.
- Enables co-located data and metadata management.
- No network hops required.
- Write-optimized backend with acceptable read performance.
- Supports lightweight ACID (atomicity, consistency, isolation, durability) properties for databases.
- Should be implemented in C++ because the extent store service is written in C++.
- Should expose external APIs similar to Cassandra because the metadata store is based on Cassandra.
After looking at multiple options, we concluded that RocksDB — an open-source KVS developed by Facebook — looked to be a great fit based on these requirements. The RocksDB properties described in the following sections helped us make the decision.
RocksDB: Embeddable C++ Library
The Nutanix extent store is completely implemented in advanced C++ (C++11/14), so our preference was to have an embeddable library that we could link with the extent store and set up the KVS in the same address space. This co-location allows local metadata lookup by avoiding process and network hops. RocksDB is a C++ library implementation.
RocksDB: LSM Storage Engine
As we mentioned earlier, the metadata store is a highly modified, Cassandra-based KVS that hosts all the metadata for Nutanix storage. Like Cassandra, RocksDB uses a log-structured merge (LSM) tree storage engine to manage all the data. Given our strong familiarity with LSM architecture, the RocksDB KVS became an obvious choice. LSM storage engines are optimized for writes and provide acceptable read and scan performance, so they support the overall goal of improving the sustained random write performance.
RocksDB is also optimized for fast, low-latency storage such as flash drives. The engine exploits the full potential of the high read/write rates that flash or RAM make possible. With the advent of storage devices like Optane and NVMe drives, RocksDB was the right platform for the new foundation.
RocksDB: APIs and Feature Set
RocksDB provides an interface in terms of keys and values, which can be arbitrary byte streams. The foundational APIs exposed are Put, Delete, Get, and CreateIterator. RocksDB stores key-value pairs in column families (similar to a table in a relational database management system). We were already familiar with this data model, and the extent store uses similar APIs to interact with the metadata store.
As Nutanix AOS is an enterprise-grade product, support for write-ahead log-based persistence and data checksums was crucial. RocksDB’s support for ACID properties through features like WriteBatch support and snapshot isolation with semantics similar to multiversion currency control (MVCC) made it attractive. Support for various data compression algorithms, diverse multithreaded garbage collection strategies (compaction strategies), a tunable caching mechanism, and an indexing mechanism for tunable data at rest showed signs of a complete subsystem.
One of the most essential and vital features of RocksDB is a pluggable persistence layer backend called Env. Env allows you to deploy RocksDB over any backend as long as the implementation complies with the Env interface. This flexibility enables support for RocksDB deployment over local file system backends like EXT4, the Nutanix block store file system, or even cloud storage backends like S3. For more details about all these features, refer to the RocksDB Wiki.
RocksDB: Open Source
Facebook developed RocksDB using LevelDB, which began as a Google project. RocksDB had been in production for various use cases at Facebook, and they were generous enough to make it completely open source. RocksDB’s active open source community, which is supported by organizations like Uber, Airbnb, and Netflix, further boosted our confidence in using RocksDB.
RocksDB Deployment for Extent Store
To bring the metadata closer to the data, we redesigned the metadata store and moved local state metadata from the original distributed metadata store to inside the extent store. We used a multiple embedded databases model, where each database is a RocksDB instance. The extent store, which is one of the components of the I/O store service, manages all the data disks hosted by that node or machine. In this mode (see the following figure), each disk hosts its local metadata in its RocksDB instance backed by the same disk.
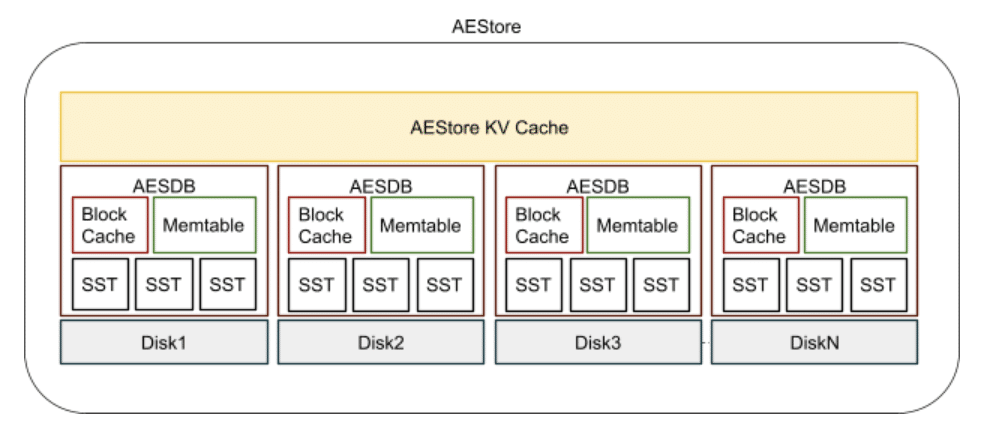
We call this newly redesigned extent store the autonomous extent store (AES), as it manages both its own data and physical layout metadata. Each RocksDB instance is an autonomous extent store database (AESDB) that holds metadata for the data on the disk where it is hosted.
Basic Setup
Starting from the bottom, the new extent store architecture uses block-based SSTables (sorted static table or sorted string table) with 4 KB data and metadata block size. We enable checksums at the data block level, while compression is disabled for the first version of AES. In the SSTable metadata, we use two-level partitioned indexes with 10-bit bloom filters for efficient point lookups. A limit of 20 and 36 SSTables causes writes to stall or stop, respectively. We use up to three skip list-based memtables, each with a maximum size of 64 MB, with default options. Each AESDB instance manages its own block cache that currently is not shared between other instances. The block cache caches metadata blocks only — the index and bloom filter blocks from the SSTables. We don’t use the block cache for data blocks because we maintain a separate AESDB key-value cache on top of all the AESDBs. The AES KV cache holds a group of logically related key-value pairs together as a single entity. Each AESDB exposes column families and stores the metadata for the extent store in a key-value format in either memtables or SSTables. We only use RocksDB’s write-ahead log (WAL) rarely because the extent store maintains its own separate WAL that ensures the durability of data written to AESDBs. We rely on the extent store’s existing WAL because of its reliability and the strong familiarity with it we’ve built over the years.
Compaction
RocksDB comes with leveled compaction as the default strategy. At Nutanix, we have used Universal compaction for the metadata store since the beginning and have stronger familiarity with it. For the first version of the AES, we, therefore, decided to stick with the universal compaction strategy and a single level.
Threading Model
Each AESDB maintains a separate thread for flush and compaction operations. This separation provides each AESDB instance the ability to make independent progress flushing the data from memtables to SSTables while performing background garbage collection.
RocksDB’s read and write APIs are sync APIs—in other words, the thread that performs the I/O operation on RocksDB is stuck until the operation is complete. Internally, RocksDB can block a thread either on resource acquisition or while performing an I/O operation to an underlying persistent medium like a disk. This behavior has a direct impact on the extent store’s performance because, when worker threads are blocked, the system’s overall throughput is reduced. We had to rework the threading model for RocksDB I/O to mitigate this issue.This particular problem and our solutions will be presented in subsequent posts.
RocksDB Use Cases at Nutanix
With the introduction of RocksDB for AES, it was clear that RocksDB would become a foundational component for many use cases, especially where we need to handle metadata for various products. In the next sections, we review current use cases for RocksDB at Nutanix. Our next set of posts in this series should cover each of these topics in more detail.
Nutanix Distributed Storage
As we’ve discussed, AES was the first use case where we introduced RocksDB in a multi-instance embedded mode. Currently, AES is deployed only on all-flash or all-high-speed persistent medium clusters. The next challenge we’re working on is to support AES using RocksDB on hybrid configurations that include both fast and slow disks.
ChakrDB: Distributed KVS Built using RocksDB
Many upcoming applications and products need a highly available and distributed KVS to comply with scale and performance requirements, which RocksDB, as a key-value library, does not provide by itself. It was evident that we needed to build a distribution layer on multiple RocksDB instances to create a standalone multi-node cluster system. As architecturally it looks similar to Cassandra’s ring design, we named it ChakrDB. (Chakr in the Sanskrit language means wheel or ring or circular.) In short, ChakrDB is a distributed KVS built using multiple RocksDB instances. We’ll talk about ChakrDB in more detail in subsequent blog posts.
ChakrDB as Metadata Store for Nutanix Objects
ChakrDB was first used in Nutanix Objects, our S3-compliant object storage product. This store manages Objects metadata along with stats stored for analytics.
Nutanix Files Analytics
Nutanix Files, an NFS-compliant file service, uses the RocksDB library to maintain local time-series data for analytics and audit functionality.
Conclusion
We started our RocksDB journey with the goal of making it a local KVS to take the extent store to the next level of performance and to make it suitable for a broad variety of use cases. Since then, RocksDB has become a foundation that manages metadata for multiple Nutanix products.
In the early phases of AES development, we used RocksDB out of the box. On our development path, we’ve tuned it to our needs and made core changes to RocksDB. We’ve learned a lot and gained a great deal of experience along the way from our frustrations and successes using RocksDB.
This blog post is just an introduction to the start of the journey — we’ll continue to share our experiences and lessons learned in subsequent posts in this series.
Acknowledgements
“It takes a village to raise a child” — This entire re-architecture effort and new journey with RocksDB would not have been possible without relentless efforts from many of our colleagues at Nutanix. We would like to thank Tabrez Memon, Chinmay Kamat, Pulkit Kapoor, Sandeep Madanala, Yasaswi K, Rituparna Saikia, Ronak Sisodia, Parmpreet Singh.
We would like to thank Nutanix leadership — Pavan Konka, Anoop Jawahar, Karan Gupta, Rishi Bharadwaj, Manosiz Bhattacharya — for their continued guidance and support.
We would also like to thank Jon Kohler and Kate Guillemette for their invaluable feedback to make this blog ready for external consumption.