

By Anoop Jawahar & Sandeep Madanala
In part 1 of this series, we discussed the motivation for building a new distributed, cloud-native, highly available, and high-performance key-value store (KVS) based on RocksDB and suitable for scales ranging from dozens of terabytes to multiple petabytes. In this post, we provide an overview of ChakrDB and its features, discuss its architecture in detail, and summarize how it helped us achieve the requirements we presented in part 1.
Overview
ChakrDB is a distributed NoSQL KVS. A ChakrDB instance is a single process, container, or pod that has multiple embedded virtual nodes (vNodes). Each vNode is an independent KVS that owns a shard in the cluster and writes all its data to remote cloud storage (which can be volumes, Nutanix virtual disks, or any virtual disk provided by clouds such as AWS or Azure). vNodes support both ext4 file system–based volumes provisioned by Kubernetes (K8s) and the Nutanix BlockStore internal file system, which is a block-based abstraction that interfaces with different types of underlying storage, including physical disks and Nutanix virtual disks. The block-based file system lets vNodes talk directly to the storage fabric, avoiding extra overhead by using ext4 over iSCSI and providing around a 50 percent boost in throughput and latency.
Salient Features of ChakrDB
Truly Elastic and Flexible
ChakrDB incorporates a sharding design based on virtual nodes (vNodes). vNodes enable linear scalability with high throughput and improved tail latency. Each vNode is a wrapper on top of RocksDB and has an entire KVS stack to itself, making it independent and providing flexibility around data movement and placement. The vNode-based design makes the cluster truly elastic, as you can simply move around the vNodes to expand or shrink it seamlessly. By their nature, vNodes are stateless entities, so moving a vNode doesn’t require you to copy storage along with it, as most cloud storage is accessible from any host or pod. This adaptability allows fast and flexible scaling as well as fault tolerance, as you can recreate a vNode in another pod to increase the pod’s CPU and memory or to accommodate failover.
Lightweight
ChakrDB is a lightweight layer on a set of RocksDB instances, adding no overhead in the I/O path because it doesn’t include replication or consensus algorithms. From our benchmark runs with single-vNode ChakrDB versus RocksDB, we’ve seen that this layer adds only negligible overhead and ChakrDB performance is almost the same as that of unmodified RocksDB.
Future-Proof
ChakrDB is designed on RocksDB, which is a KVS based on a log-structured merge (LSM) tree. The LSM data structure is optimized for SSDs and works well with NVMe devices. It also clears the way for several new architectures such as remote storage, key-value separation to reduce write amplification, and so on. As the open-source RocksDB community continues to explore new storage technologies such as in-storage computing and storage-class memory (SCM), we can expect the architecture to remain future-proof.
ChakrDB itself is also prepared for the future; while today each vNode uses RocksDB as its storage engine under an abstract KV layer, we have the option to plug in to other engines as needed later on.
Cloud or Remote Storage
Many of today’s cloud-native applications serve use cases that require tiering cold data to remote storage such as S3 or storing data in a cloud (Elastic Block Store (EBS), Azure managed disks, and so on). As in-storage computing devices become more common, researchers are investigating how to offload background tasks such as compaction to remote devices as well. To accommodate all such use cases, it’s important for DBs to support remote storage.
Pairing the RocksDB environment with the Nutanix block store layer allows ChakrDB to run on any type of cloud or remote storage. To date, we’ve run ChakrDB on physical disks, Nutanix virtual disks, and even in Azure using Azure storage with the Azure Kubernetes Service (AKS).
Architecture
Each instance of ChakrDB has several internal modules.
API Interface
Today, the API interface layer exposes APIs that are based on key-value data; we’re working to expose more feature-rich APIs in later iterations. Because ChakrDB uses RocksDB APIs with a lightweight distribution layer, applications that use RocksDB can easily use ChakrDB instead.
SchemaManager
SchemaManager orchestrates the schema manipulation workflows across the vNodes in the ChakrDB cluster.

BgTaskManager
This module tracks vNode performance by monitoring background tasks such as compaction, flush, table creation, and garbage collection (GC) in each vNode. It collects all the necessary statistics, analyzes them, and takes corrective action (invoking flush, compaction, and so on) when required.
VNodeManager
VNodeManager coordinates all vNode life cycle operations such as starting or stopping a vNode while also managing all I/O to the vNodes. This module distributes I/O from the client across multiple vNodes, gathers the vNode responses, and sends them back to the client. The vNode manager also makes decisions related to sharing resources across vNodes.
ChakrDB Cluster
Now, let’s look at where you can deploy the ChakrDB cluster. Because it’s containerized, ChakrDB can run on any K8s environment in pods. You can host the K8s platform on Nutanix distributed storage or any cloud storage provider (AWS, Azure, and so on).
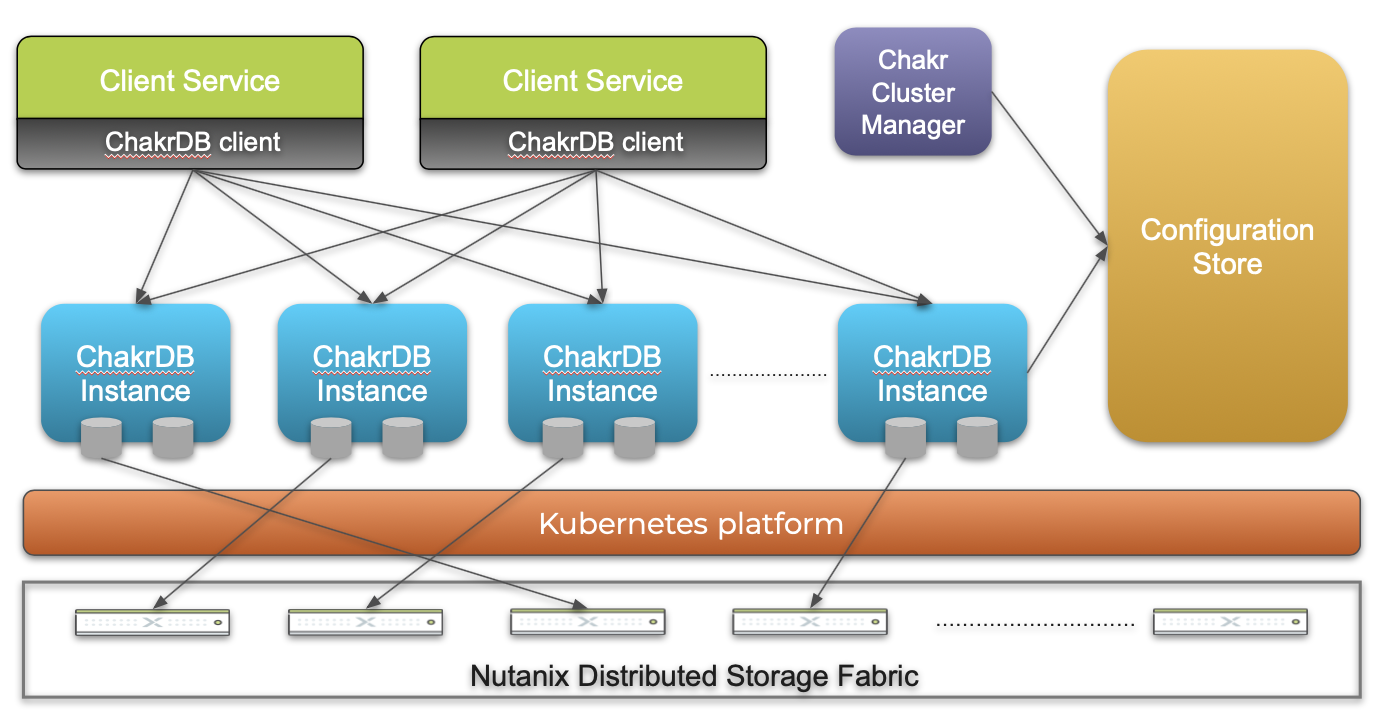
There are four major components in the ChakrDB cluster.
ChakrDB Instance
The ChakrDB instance, which is the core piece that manages the entire data path, hosts the vNodes and their storage, which can be from Nutanix, AWS-EBS, or Azure.
Chakr Cluster Manager
The Chakr Cluster Manager handles all the control plane traffic in the ChakrDB cluster. This module makes the majority of decisions in the cluster, such as how many ChakrDB instances to start the cluster with, the number of vNodes hosted in a ChakrDB instance, how shards map to vNodes, how vNodes move across instances during scale-out, and so on. Once Chakr Cluster Manager has established this configuration, it stores it in the configuration store. We’re currently developing a K8s operator to automate all these control plane workflows on any cloud K8s platform.
Configuration Store
The configuration store persists all ChakrDB configuration details, including shard mapping, instance information, and database schema. Currently stored in Zookeeper, this module is the central source of state settings for all ChakrDB instances and vNodes.
Client Library
Client services can use the ChakrDB client library to talk to ChakrDB instances. This client library fetches the shard mapping from the configuration store and uses that information to send requests directly to the appropriate ChakrDB instances to avoid extra hops. It also distributes any client request across multiple ChakrDB instances, gathers responses from them, and sends them back to the client.
Architecture Highlights
ChakrDB can scale linearly both inside and out. You can scale vNodes within a ChakrDB instance, and ChakrDB instances can scale themself linearly to expand the cluster. All these workflows are designed so that they occur seamlessly in the background and don’t interfere with user I/O.
Strong consistency and resilience are key requirements for any storage software. Any cloud K8s platform (like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS)) can provide highly available compute and memory, while any highly available cloud storage (like EBS, Azure managed disks, or S3) can provide consistent and highly available storage. Because the underlying cloud platform already supplies compute, memory, and storage high availability (HA), we didn’t need to build additional replication into ChakrDB, making it a very lightweight DB distribution layer.
To better tolerate host failures, we’ve added antiaffinity rules such that you can’t deploy two ChakrDB instances on the same host in K8s.
ChakrDB is designed for performance and scale. Its vNode-based sharding design keeps RocksDB from being a write-ahead log (WAL) bottleneck and distributes I/O across multiple RocksDB instances, achieving parallelism and greatly improving write throughput. Read throughput gets a similar boost from using parallel underlying storage virtual disks across RocksDB instances, which lets ChakrDB take advantage of the full potential of a distributed storage fabric.
For improved performance, you can deploy ChakrDB either in embedded or remote mode. In embedded mode, client services like Nutanix Objects (a blob storage service similar to Amazon S3 or Azure Blob Storage) can embed a ChakrDB instance as a library in its process space. This functionality lets the services talk locally to the embedded instance while also talking remotely to other ChakrDB instances. Deployment in embedded mode can achieve low latency for metadata by cutting down on remote procedure call (RPC) overhead.

Embedded mode works very well for stateful services. We integrated ChakrDB with Objects so that the shard mapping of MetadataService (the stateful service managing metadata for Objects) overlaps with ChakrDB’s shard mapping. Therefore, in embedded mode, requests that reach a MetadataService instance based on its own sharding logic are always served by the local embedded ChakrDB instance. With this close integration and a guarantee that the local ChakrDB instance serves all the data for a MetadataService shard in Objects, MetadataService can maintain a caching layer while achieving read-after-read consistency and experiencing greatly improved throughput and latency.
Scalability
We tested ChakrDB in production, deployed as part of Nutanix Objects, on our internal clusters. Here are some of the results we achieved when stretching the deployment to a very large scale.
Note: Real-world production clusters would take a long time to reach this scale.
- The largest cluster our QA team deployed had around 1,024 ChakrDB instances, with 4 vNodes in each ChakrDB instance, totaling around 4,000 vNodes in the cluster.
- One of our internal clusters pushed around 25 TB of data with around 75 bytes of keys in a 128-node ChakrDB cluster, or around 200 GB with 600 MB of keys per ChakrDB instance and 50 GB with 150 MB of keys per vNode.
- A ChakrDB instance with 11 GB of memory handled around 8 bytes of keys and around 1.6 TB of data. This instance contained 8 vNodes, and each vNode held around 230 GB of data with 1 byte of keys. This result shows ChakrDB’s resource efficiency.
- We deployed most of these ChakrDB clusters on a four-node Nutanix cluster, which shows how well ChakrDB can take advantage of the underlying distributed storage fabric’s full potential.

The preceding graph shows the throughput we achieved when scaling ChakrDB instances linearly. There is still scope for improvement in these numbers, and we plan to provide more detailed results for read, write, and scan operations in the next set of ChakrDB blogs. A recent talk we gave at Percona Live covers ChakrDB architecture in some detail as well as some recent RocksDB enhancements.
Conclusion
ChakrDB is steadily becoming the KVS born in the cloud, for the cloud. Several customers are running ChakrDB today in their Objects deployments with good results, relying solely on infrastructure HA for storage, compute, and memory.
Even when they’re very small, bugs at the RocksDB layer can percolate into storage. We’re looking at adding possible asynchronous backup techniques or checksum calculations at various stages to protect against these bugs. The latest RocksDB versions have better checksum techniques to catch software corruption before it becomes persistent.
As described in the previous section, we’ve achieved excellent ratios for data to memory usage and throughput to CPU usage.
We’ve established linear scalability within an instance through multiple vNodes and at the instance level by adding multiple instances. We still have more work to do here to optimize and reduce overhead in linear scaling at the client library and VNodeManager layers.
We haven’t broken deployment scaling or hit any major bottlenecks with large clusters on the K8s-based Nutanix microservices platform (MSP), which means that we can store hundreds of terabytes of key-value data in a single cluster. In general, cluster size would be limited by node storage capacity or clients that aren’t distributed. A distributed or embedded client can scale to a very large number of nodes as well as a very large amount of throughput and storage.
Our extensive tuning of the ChakrDB threading model across RocksDB read, write, and compaction operations has helped to improve performance, and we plan to provide a detailed analysis of RocksDB and ChakrDB performance efforts in a future blog.
The Nutanix Objects product (with ChakrDB) is popular for its high performance and scalability. It’s under consideration for several high-performance, large-scale S3 workloads like big data analytics, machine learning (ML), and artificial intelligence (AI) alongside backup and secondary storage workloads.
ChakrDB is evolving into a KVS with the following capabilities to support hybrid multicloud deployments:
- Cloud-native: Can run in any cloud based on a K8s platform.
- Any cloud storage: Can write data to any cloud or remote storage that can attach to containers on a K8s platform.
- Cloud-style easy workflows: Deployment, scale-up, and scale-out workflows take advantage of K8s and software-defined storage.
- Strong consistency, HA, and resilience: ChakrDB uses cloud infrastructure capabilities to avoid the complexities of added replication and distributed consensus protocols.
- Scale-out performance and low latency: A RocksDB foundation with a lightweight distribution layer allows for very high performance and low latency for applications at cloud scale.
Nutanix is prototyping ChakrDB in multiple ongoing projects and products with promising initial results:
- At the caching or staging layer for long-term backup software.
- As a replacement for our core Cassandra implementation in AOS.
- As a distributed storage engine for Postgres.
Even though we started ChakrDB as a plain KVS, we’re seeing increasing demand for several advanced features, including:
- Secondary indexing.
- vNode expansion and the ability to move vNodes across instances freely and easily.
- Distributed transactions across vNodes.
As our work on these and other features continues, we plan to keep updating you on our progress in future blogs. We also plan to make our ChakrDB work open-source so that the RocksDB community that has helped us so much can share in the benefits.
Acknowledgments
This effort was powered by the entire ChakrDB team: – Parmpreet Singh, Rituparna Saikia, Ronak Sisodia, Sweksha Sinha, Jaideep Singh and Yasaswi Kishore.
Big thanks to Karan Gupta for the continued guidance in architecting and designing this project. We would also like to thank Dheer Moghe and Kate Guillemette for the detailed content review and feedback.