

By Harshit Agarwal and Gary Little
Introduction
On the Nutanix distributed file system (NDFS), a virtual disk (vDisk) represents a flat logical storage space that can be consumed by a client (VM or container) in the form of a disk. The system is designed in such a way that it is able to use all the resources of a cluster effectively when there are multiple such vDisks on every node performing I/Os. However, there are times when user workloads don’t span over multiple vDisks. For example, if a customer wants to migrate from a legacy 3-tier setup with a few huge volumes on Nutanix hyperconverged platform, the storage service may not provide the maximum performance even though there are resources (CPU, disk bandwidth, and memory) available. These use cases are not limited to lift-and-shift workloads; we see single vDisk performance being critical in the following scenarios as well:
- Applications don’t support the use of multiple disks.
- Benchmarking scenarios during proof of concept compare one vDisk’s performance on Nutanix HCI with traditional systems.
Challenge
AOS storage manages all I/O with a process called Stargate, which has a controller for each vDisk. While running a workload such as random reads, the vDisk controller was not able to use all of the available CPU capacity in the Controller VM (CVM), but was getting limited to a single CPU. The vDisk controller is single threaded by design, which lets us access all the data structures holding vDisk state lock free, simplifying the code and making it efficient. The overall system performance scales with the number of vDisks, but the performance of a single vDisk is limited by the performance of a single CPU core/thread.
Solution
To overcome this challenge, we needed to either add more compute for processing single vDisk operations or reduce the amount of CPU these operations consume. In this case, we did both. In AOS 6.1, to add more compute, we chose to have multiple controllers with one thread each instead of multiple threads working on the same controller object. This maintains the single thread guarantee on almost all the controller state; only the common state is shared and accessed through a custom locking interface that requires a read or write lock based on the type of access. The unique I/O ranges are effectively distributed across these controllers based on the offset, “sharding” the vDisk. The I/O distribution approach is quite common in storage systems; however, what is uncommon is the fact that these ranges are not tied to the corresponding shard. This design keeps the number of shards/controllers completely dynamic.
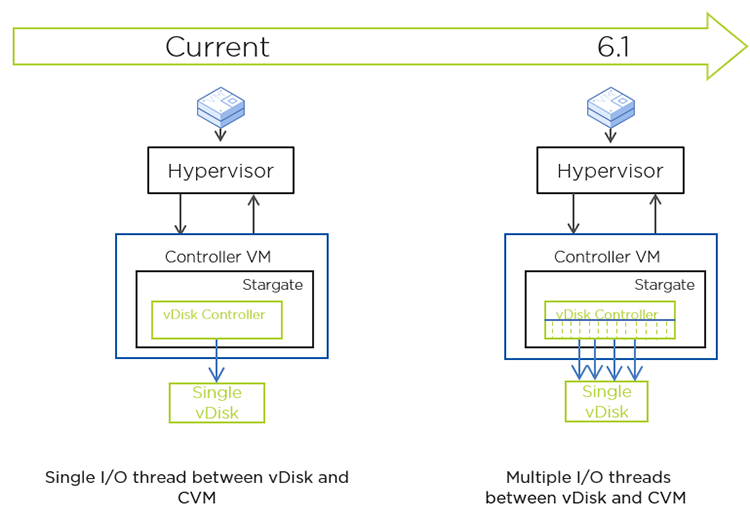
External components interact with only one controller, keeping the interface and API contract the same as with a regular vDisk. All the changes are encapsulated within the vDisk controller layer. The external facing controller is designated as primary and is responsible for distributing the I/O to the n shard controllers that actually perform the I/O.

As mentioned earlier, the number of shards or controllers for a given vDisk is dynamic and can change during the lifetime of a vDisk without data migrations or metadata updates. This allows for adding or removing the controllers based on the amount of compute needed to handle a given workload. Whenever there’s a change in the number of controllers, the ranges are automatically remapped to their corresponding controller. By keeping the ranges unique, we minimize the locks needed in the I/O path especially for the shared state among various controllers, thus linearly scaling the performance with the number of controllers.
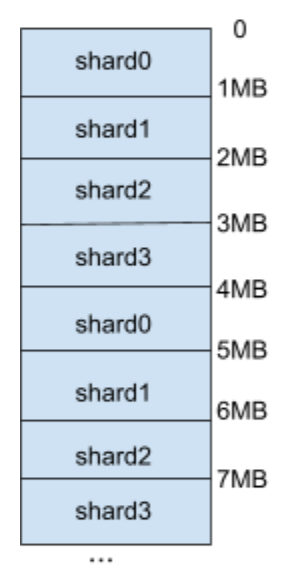
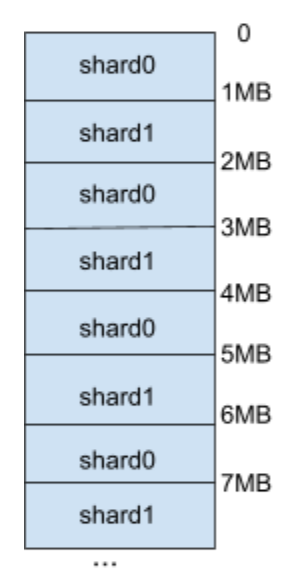

We let the vDisk take more resources as needed but also made the I/O path more efficient by adding the capability in the I/O path to track the physical CPU usage and using CPU profiling tools such as flame graphs to identify bottlenecks. We ran multiple iterations with each profiling tool, identifying a few CPU hotspots, fixing them, and then running the profiling again to identify the next one. As expected with this exercise, we not only improved vDisk performance when sharded but also the performance for the regular vDisk case.

Performance
The benchmark results show the value of the solution. Since many of our customers are running SQL Server, where a single disk is a common deployment method, we added SQL Server benchmarks to our normal storage performance microbenchmarks.
Ideally we would like to improve the performance of small random read workloads because:
- They are the dominant pattern of many database workloads. For example, TPC-E, the most recent transactional TPC benchmark specification, has a ~9:1 R:W ratio.
- Small random reads are computationally sensitive because the I/O size is very small and there is a large fixed CPU portion for a given I/O. In other words it takes almost the same amount of CPU to move 1 MB as 4 KB, so it takes much more CPU to move say 1 GB in chunks of 4 KB than in chunks of 256 K. Since the access pattern is unpredictable (random as it appears to the storage), we cannot use any pre-fetch tricks to gain efficiency.
As expected, given the sharding goal of improving CPU efficiency and scale,we saw an improvement of 172% for 8 KB random read workloads.

We also wanted to make sure that the microbenchmark gains translated into improved application performance. To track this, we measured both the improvement in transactional performance for an I/O intensive database workload using HammerDB and Microsoft SQL Server and the time to restore a database contained on a single drive.
The transaction rate improved by 78% when using an AOS release with vDisk sharding and the restore process was 32% faster.

Wrapping Up
It was great to achieve such a sizable performance gain for single vDisk workloads directly visible in a commonly deployed application. The fact that we were able to improve both efficiency and scale at the same time is what allowed such gains.