

Summary
The goal of this article is to show how customers can land their next generation AI workloads on Nutanix Cloud Platform (NCP). As a first step, we show how one can implement the Attention mechanism from scratch on NCP. Attention is the core concept behind the cutting edge generative AI models and Large Language Models (LLMs). Hence we chose to demonstrate how the core or the kernel of the latest AI models can be easily deployed on Nutanix AHV. We go deep into the Attention mechanism to give our users insight into these models, while showing them the simplicity of our platform.
Use Cases for Nutanix
Many enterprises need support for running advanced AI/ML models so that they can extract value out of stored data. Here are a few examples:
- Visual perception e.g., optical character recognition, object detection
- Automated chatbot e.g., ChatGPT and numerous variants
- Speech recognition systems e.g., Siri, Alexa, Google assistant
- Retail e.g. Amazon Go
For these models, Attention is used as a fundamental building block. Therefore, it is critical that our customers understand the basic mechanisms and also have the ability of running Attention from scratch on the Nutanix cluster. The following figure shows how AI/ML is being integrated into the core Nutanix infrastructure layer. The Attention based Transformer models take a central role in this integration. We strive to ensure customers can build a wide array of AI apps such as NLP, vision, contact center, recommendation, etc. by enabling the Attention mechanism from scratch.
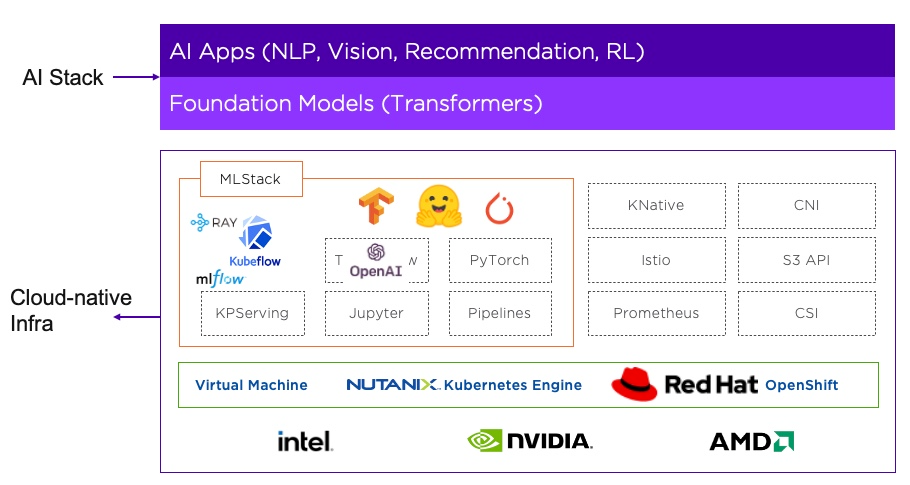
Introduction
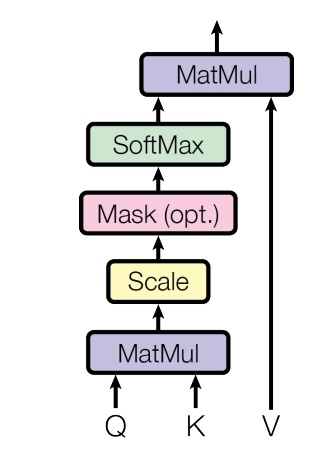
ChatGPT has captivated human/societal attention and has accelerated the AI transformation of the Enterprise. It demonstrated the power of Attention mechanisms as it dispenses the need for recurrent neural networks (RNNs), long short-term memory (LSTM), and convolution neural networks (CNNs) in sequence modelling. Hence we start our Nutanix AI journey with a deep dive of the Attention mechanisms.
For a token in an input sequence, the attention mechanism is used to weigh the importance of different parts of the input sequence by assigning weights relative to the token. The Attention mechanism is implemented using self-attention. In self-attention, the input sequence is transformed into three separate vectors:
- Query (Q)
- Key (K)
- Value (V)
Query vector corresponds to the current token being processed, while Key and Value vectors correspond to all other tokens in the input sequence. The attention is expressed as a function of (Q, K, V):
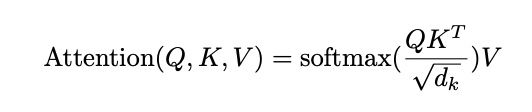
In the following sections, we will implement the Attention mechanism from scratch.
Setting up Nutanix Infrastructure for Attention
- Log into Prism Element
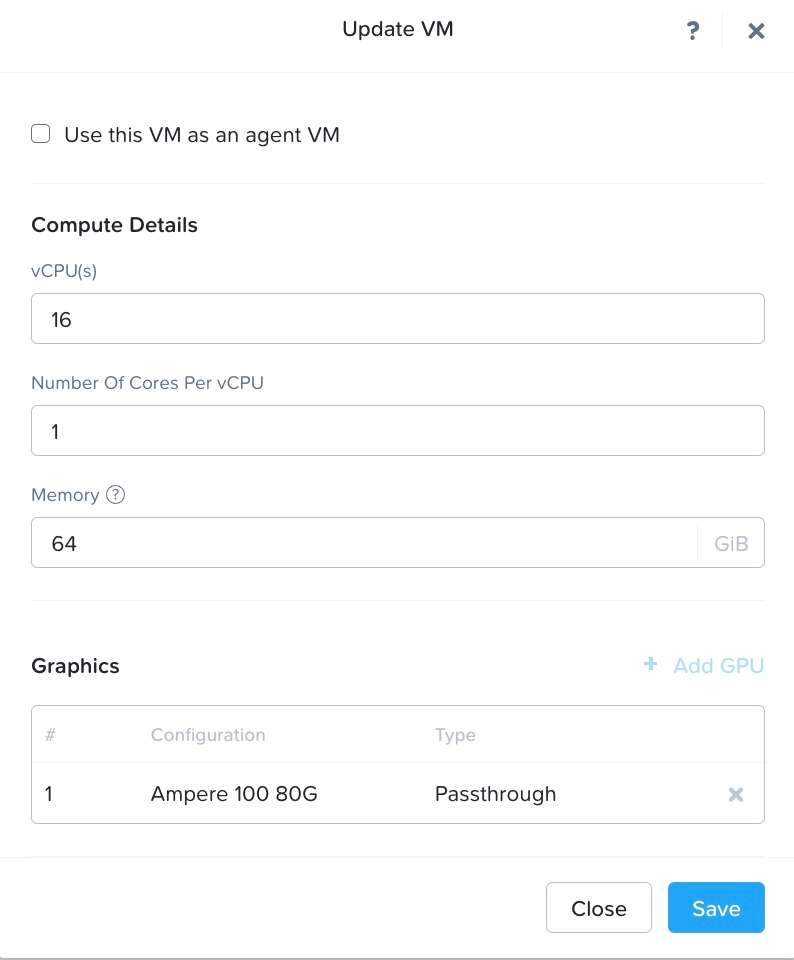
- Set up the VM. We set up a VM with appropriate resource configurations. For this article, we have used the following VM spec:
- 16 single core vCPUs
- 64 GB of RAM
- NVIDIA® A100 tensor core passthrough GPU with 80GB memory. The GPU is installed with the NVIDIA® RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run).
- Ubuntu 22.04 operating system
On running the nvidia-smi command, we get the following output. It shows the Driver version to be 525.60.13 and CUDA® version to be 12.0.
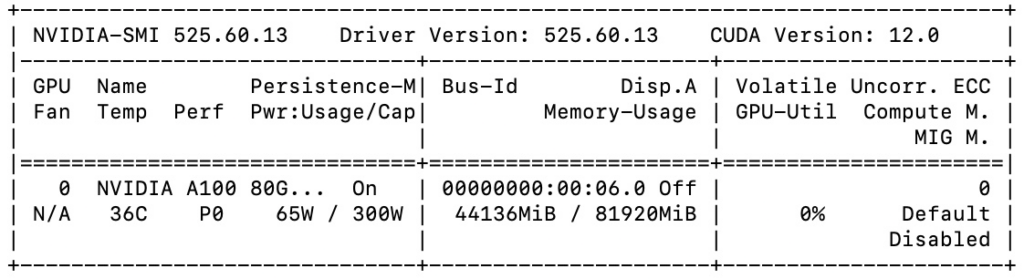
nvidia-smiIt also shows other GPU specifications as mentioned in the following table.
| Item | Value | Description |
|---|---|---|
| GPU | 0 | GPU Index |
| Name | NVIDIA A100 | GPU Name |
| Temp | 36 C | Core GPU Temperature |
| Perf | P0 | GPU Performance |
| Persistence-M | On | Persistence Mode |
| Pwr: Usage/Cap | 65 W / 300 W | GPU Power Usage and it capability |
| Bus Id | 00000000:00:06.0 | domain:bus:device.function |
| Disp. A | Off | Display Active |
| Memory-Usage | 44136MiB / 81920MiB | Memory allocation out of total memory |
| Volatile Uncorr. ECC | 0 | Counter of uncorrectable ECC memory error |
| GPU-Util | 0% | GPU Utilization |
| Compute M. | Default | Compute Mode |
| MIG M. | Disabled | Multi-Instance Mode |
Implementation of Attention Mechanism
- We take an input sentence, assign an index to each word based on alphabetical order, and compile a dictionary of {word: index}.
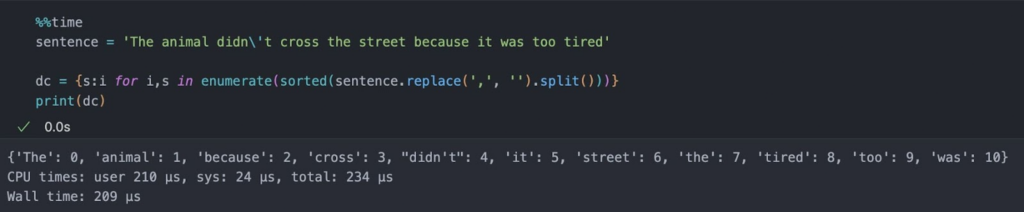
- Next, we use this dictionary to assign an integer index to each word:
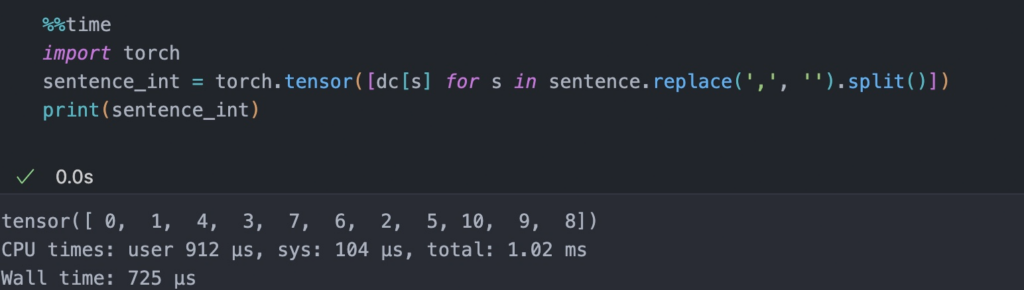
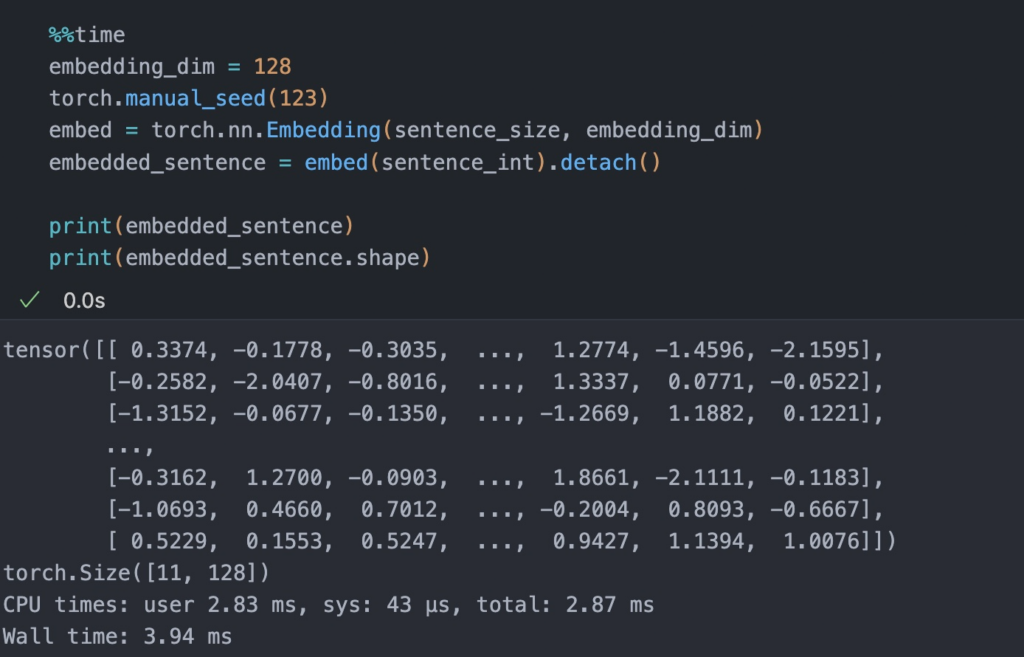
- Now, using the integer-vector representation of the input sentence, we can use an embedding layer to encode the inputs into a real-vector embedding. Here, we will use a 16-dimensional embedding such that each input word is represented by a 16-dimensional vector. Since the sentence consists of 11 words, this will result in a 11 x 16 dimensional embedding. The choice of embedding dimension is completely arbitrary.
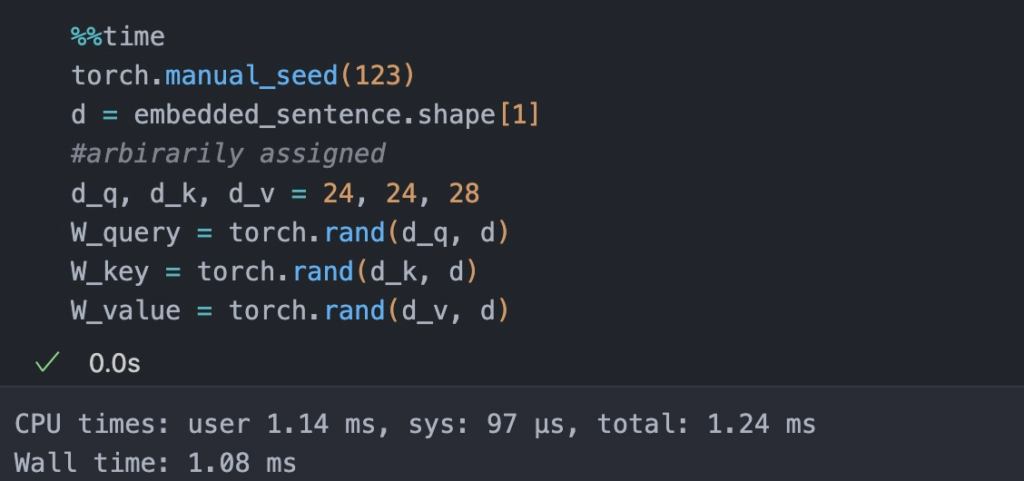
- Next, we define three weight matrices for Q, K, and V. Self-attention utilizes three weight matrices, referred to as Wq, Wk, and Wv, which are adjusted as model parameters during training. These matrices serve to project the inputs into query, key, and value components of the sequence, respectively.
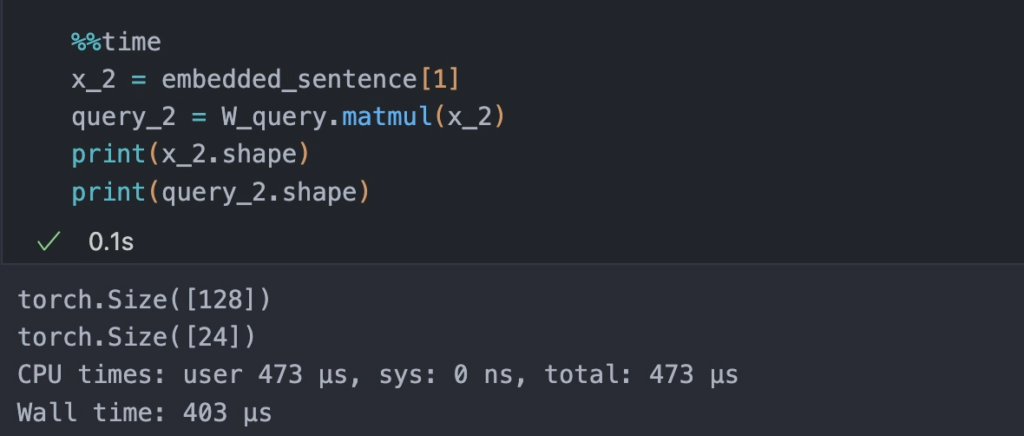
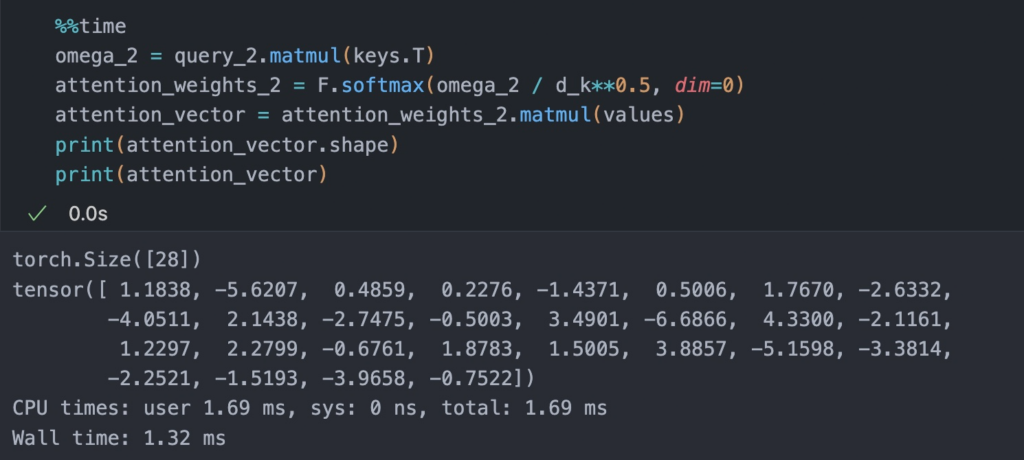
- Now suppose we are interested in computing the attention-vector for the second input element – the second input element acts as the query here.
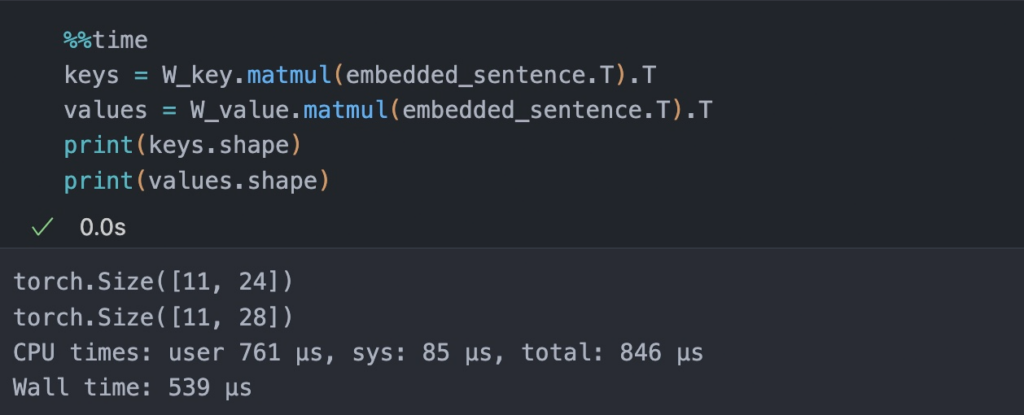
- Next, we compute K and V for the input sentence.
- Finally, we compute the attention vector using the formulation proposed by Vaswani et al.
Self-Attention Visualization
The chart below shows the visualization of the self-attention mechanism in action for the test sentence: “The animal didn\’t cross the street because it was too tired.” for the word “animal”. The word “animal” in the test sentence is most strongly related to itself as per the attention score. Other important words seem to be “was”, “tired”, “it”. These words capture the words with high importance or high information content with respect to the word “animal.” Also, it is to be noted that the attention model is untrained and the weight vectors are fully randomized. The attention scores will be more informative after a thorough training.

Conclusion
Thus we have shown how we can leverage the Nutanix Cloud Platform to land the broad class of attention/transformer based AI models on very modest infrastructure. This is the heart of the current wave of generative AI, LLMs etc. NCP allows customers to achieve consistency across their entire infrastructure stack, from edge to the cloud. In addition, we believe that NCP can help customers with their ROI for intense AI workloads by a combination of class leading unified storage, better integrated management, operations and security, along with data management and governance.
References
“Attention is all you need”, NIPS 2017 – Vaswani et al.
Appendix
Use Cases of Attention-based AI Models in the Industry
- Visual perception e.g., optical character recognition, object detection.
- Automated chatbot e.g., ChatGPT and numerous variants.
- Speech recognition systems e.g., Siri, Alexa, Google assistant.
- Automated decision-making systems e.g., AlphaGo.
- Robotics e.g., retail packaging, manufacturing pipelines.
- Predictive healthcare e.g., early disease recognition, AI driven protocols in cancer.
- Drug discovery e.g., AlphaFold, high throughput docking.
- Compliance e.g., named entity recognition, contract understanding.
- Legal e.g., document summarization, compliance enforcement.
- Manufacturing e.g., predictive maintenance tasks.
- Transportation e.g., autonomous vehicle tasks.
- Developer productivity e.g, code completion.
- Retail e.g. reducing shrinkage, visual supply chain, fraud detection.