

Whether it be virtual machines, files or even Acme Corporation Whatsits, querying a large set requires a little thought. Quick intro note – for the purposes of this article we’ll define large as more than 500 items, even though many environments are much larger.
Consider the following basic scenario:
- A Nutanix environment with clusters running Acropolis 5.10.5, the latest version as at June 13th 2019 (note that the API requests in this article work the exact same way on Nutanix Community Edition).
- One of the clusters is host to 1407 virtual machines. This seems like an arbitrary number but will make more sense shortly.
What about the questions that may arise when querying that set of VMs?
- Do we want to group them into “chunks” of 20?
- Chunks of 100?
- Chunks of 500?
- Where do we want to start when making those queries?
- Do we start from “the start”?
- Do we want to skip the first 103 VMs?
Questions, questions … 🙂
Default v3 API “list” queries
Here is a simple query to list VMs in a cluster.
URI: https://{{cluster_ip}}:9440/api/nutanix/v3/vms/list
JSON payload: {"kind":"vm"}
Method: POSTWhat is the response from that request? In our cluster of 1407 VMs, we’ll get a JSON response with two main things to look at.
- metadata object, containing:
- total_matches – The total number of VMs in the cluster
- length – The number of VMs in this query only
- offset – Where the query started, relative to the first VM at index 0
- entities list – a zero-indexed list of entity-specific data
In the simple query above, let’s look at the JSON response. In particular, the metadata and opening part of the entities list.
{
"api_version": "3.1",
"metadata": {
"total_matches": 1407,
"kind": "vm",
"length": 20,
"offset": 0
},
"entities": [
...
]
}That looks very much as you’d expect. However, out of 1407 VMs only 20 were returned as part of the response. Why?
One consideration when architecting APIs is exactly what you’re seeing above. Let’s pose it as a simple question: “If the user doesn’t specify a number, how many entities should we return by default?” No doubt there are many schools of thought on that but, when using the Nutanix v3 APIs, the answer to our question can be worded in two parts, as follows:
Without specifying the number of entities to return, the v3 list APIs shall return a maximum of 20 entities. If the number of entities is specified, the maximum number of entities that shall be returned is 500.
– N/A
What you are possibly thinking is correct. If you don’t specify an entity count, you will get 20 entities in your request, assuming there are 20 to return. Conversely, no request will return more than 500 entities, even if there are more to return.
Parameters “offset” and “length”
With that mostly intro stuff out of the way, let’s consider this from a practical perspective. For our article today, we don’t want only 20 VMs returned from our total of 1407 – we want more. To start controlling these things, we can use the offset and length parameters in our JSON payload.
Our earlier API query can be rewritten as follows.
URI: https://{{cluster_ip}}:9440/api/nutanix/v3/vms/list
JSON payload: {"kind":"vm","length":500,"offset":0}
Method: POSTWhat has changed?
- The URI is the same
- The method is the same
- The payload has changed to include both length and offset parameters.
Comparing the response from that request to our earlier response, this is what we get:
{
"api_version": "3.1",
"metadata": {
"total_matches": 1407,
"kind": "vm",
"length": 500,
"offset": 0
},
"entities": [
...
]
}The big difference? Yes – we are now getting our VMs returned in “chunks” of 500 at a time. In this response, we now have VMs 0-499. We’re still starting at index 0, although we’re about to dig into that a little more.
The real world
You can see where we’re going with this now. Combining the length and offset parameters allows us to iterate over our large VM set and grab almost any number of VMs, starting at any point.
In the real world, some basic math is going to be required. For example:
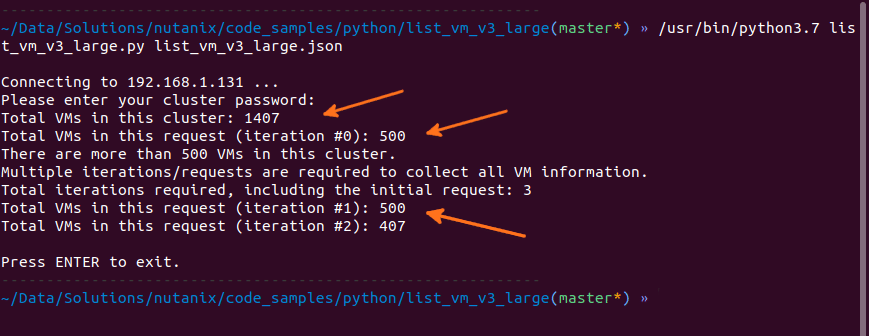
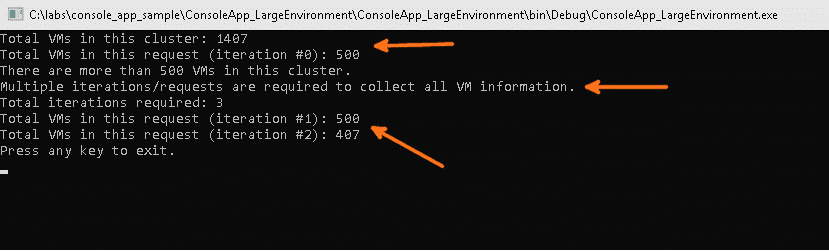
- With a total of 1407 VMs and a length value of 500, we know that we’ll need a total of 3 requests to capture all VMs.
- The first request is one we’ve already done i.e. VMs from index 0 to index 499 – a total of 500 VMs.
- For the remaining VMs, we don’t want to send unnecessary duplicate requests, so we can use the offset parameter to start the second iteration at index 500.
- For the final iteration, we can set the the offset parameter to 1000, in order to request the final 407 VMs. The final request payload is as follows. Note: we’re still using a length of 500, even though “only” 407 VMs are being returned. Using a length of 407 would yield the exact same result.
{"kind":"vm","length":500,"offset":1000}And the response:
{
"api_version": "3.1",
"metadata": {
"total_matches": 1407,
"kind": "vm",
"length": 407,
"offset": 1000
},
"entities": [
...
]
}Usage Example
A short while ago we introduced the new Code Samples section of the Nutanix Developer Portal. As part of that sample code collection, there are two samples that relate specifically to this article. Both are hosted on the Nutanix Developer GitHub code samples repository and are available for you to use immediately.
Wrapping up
What are the key takeaways from this article?
- Unless you specify otherwise, a Nutanix v3 API list request will return a maximum of 20 entities
- The length parameter can be used to specify exactly how many entities you want returned, up to a maximum of 500
- The offset parameter can be used to specify the query’s starting point, relative to the first entity at index 0
Hopefully this content makes it a little easier to understand how the Nutanix v3 APIs can be used in larger environments. Please do feel free to get in touch any time if there’s any specific content you’d like to see.
If you’d like to learn more, our Director of Engineering, Raghavan Kollivakkam, has written two fascinating blog posts about API architecture – definitely check them out!
Thanks for reading!