

We started this blog series by describing the unique Dynamically Distributed Storage architecture of AOS to highlight how Nutanix engineers took on the difficult approach of dynamically distributing data across a scale-out cluster for resiliency and low-latency performance.
Here, in our second blog, we dive deeper to show how AOS splits VM vdisk data into fine-grained 4MB chunks called extent groups. This is a more elegant approach than relying on giant static blocks that are inefficient to store, network sensitive to protect, and slow to rebuild. Extents in AOS are made possible by a distributed metadata store, an approach that will sound familiar to cloud architects as a way to consistently and efficiently keep track of distributed data during optimal conditions and during failure modes, the latter being where storage architects focus their attention.
Distributed Scalable Metadata
As mentioned in the previous blog, AOS intelligence is divided and spread across the cluster into services inside a Controller Virtual Machine (CVM). Metadata in AOS is broken into a global and local metadata store. The global metadata stores logical metadata like which node the data is stored on while the local metadata stores the physical metadata like which exact disk and region the data is stored on. This provides flexibility and optimizes updates to metadata.

The global metadata store is a distributed store based on a heavily modified version of Apache Cassandra and uses the Paxos algorithm to enforce strict consistency. Metadata is stored in a distributed ring-like manner to provide redundancy. The local metadata store keeps physical metadata related to the local physical node in an Autonomous Extent Store (AES) DB which is based on RocksDB. More details around what kind of metadata is stored where, and how it is stored can be found in the Nutanix Bible.
Dynamic App-Aware Data Management
The distributed metadata store allows AOS to split vdisks into fine-grained data pieces for storage delivering dynamic and automated data placement and management. Nutanix writes data to 2 or 3 places in the cluster depending on replication factor (RF). When an application writes data, AOS makes a dynamic selection as to where the data copies for it will be placed, every single time. One copy of that data is always placed on the node where the application is running. AOS places the other copies intelligently depending on the cluster availability domain. If the cluster uses the default node aware domain, a different node is selected. If the cluster is using block or rack awareness, a node in a different block or rack is selected. For the 2nd and 3rd copy of data of a new write after that, the same node, block, or rack is not selected. AOS ensures it spreads the data copies equally across the cluster to keep the cluster balanced. Even when selecting which disk the data copies will be placed on (both local and remote copies), the disk selection is done by an intelligent algorithm that computes disk fitness scores based on usage, response time and queue depth.
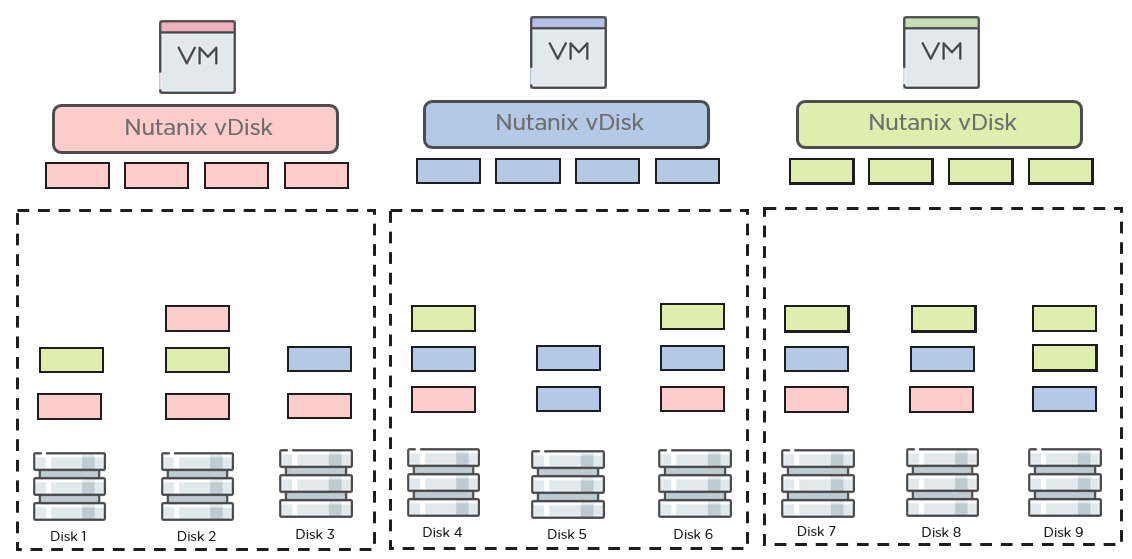
The fine-grained app-aware data storage also makes it easy for AOS to automate management of data on the cluster and recover from failures instantly. For example, if a node in the cluster has to be put in maintenance, the VMs on it are moved to another node. If the data requested by the application in those VMs is not local to the node where it moved, AOS will automatically move the requested data to that node when it determines it is being requested multiple times. If there is a failure in the cluster like a node, disk, or CVM becoming unresponsive, AOS can quickly and easily determine which data copies are no longer available thanks to the distributed metadata store and immediately starts the rebuild process. The creation and placement of these recovery data copies is also done automatically, dynamically and independently. Not only is the process immediate but during failure and recovery, new writes and overwrites of existing data are instantly protected and still done according to RF policies ensuring higher resiliency for the application.
To distribute and manage data:
- AOS makes a placement decision of each data copy independently.
- One copy is always kept local to the node where the application is running.
- Other copies are spread equally across the cluster based on an algorithm and the availability domain configuration of the cluster.
- Data is automatically moved between nodes and between tiers by AOS if a VM moves to ensure the requested copy of the data remains local
- During failures, rebuild of data copies is done immediately ensuring data availability.
Why Does This Matter?
AOS ensures consistent and predictable performance for applications and their data without the need for upfront design guesses or estimates. AOS makes flexible and dynamic decisions as applications create and access data ensuring overall better consistency in performance and usage. Application performance remains consistent and fast as AOS keeps data local to nodes where the application is running by eliminating network hops.
Missing data copies are immediately rebuilt by AOS during failures thanks to fine-grained metadata and distributed placement. Not only is the process immediate, because intelligent decisions were made while placing them initially by distributing them dynamically across multiple nodes and disks, during recovery, multiple nodes and disks take part in rebuilding making it very quick. The recovery process in fact becomes quicker as the cluster size grows. There are no bottlenecks created in the system where a particular node or disk can get overwhelmed doing recovery, affecting application performance. AOS optimizes recovery speed for data ensuring data becomes highly available as soon as possible, enabling applications to return to optimal performance sooner.
This Nutanix design, quite difficult to implement, provides app-centric optimization, ensuring consistent performance throughout the lifecycle of the application being deployed and better data availability and overall resiliency.
In the next blog we will see how this unique distributed architecture with fine-grain data distribution allows for seamless cluster management of performance and capacity without manual intervention.
Check out part 1 of this series: Nutanix Benefit 1: Dynamically Distributed Storage.