

Summary
Due to significant advancements in machine learning over the past few years, state of the art models have achieved impressive milestones and can now be applied to a wide range of complex tasks. In order to achieve this, one needs to manage the lifecycle of models. This is known as MLOps. MLOps consists of workflows for the different pieces of the lifecycle including training, inference, hyperparameter tuning etc.
To enable real-time decision making, ML Models must process inference requests fast and cost-effectively. Deploying them in production must be as streamlined as possible. In this blog post, we will demonstrate how the KServe inference platform works on Nutanix Kubernetes Engine which is a part of the Nutanix Cloud Platform, and can be utilized to easily deploy modern ML models for inference in production. This addresses the common workflows for the inference stage of the MLOps pipeline.
In this article, we will use “CompVis/stable-diffusion-v1-4” as an example for real-time inference using Kserve on Nutanix Cloud Platform. Kserve is a scalable, highly performant model inference platform built on Kubernetes.
Quick Intro: Stable-Diffusion-v1-4
Stable Diffusion is a deep learning model which can generate an image given a textual prompt.
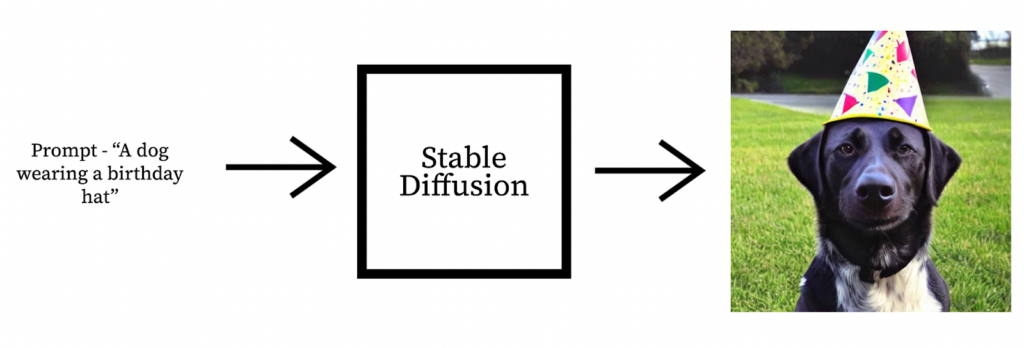
From the diagram we can have a textual prompt like “A dog wearing a birthday hat” passed as input and the Stable Diffusion model can generate an image representative of the text.
Official repo: Stable-Diffusion-v1-4 on GitHub.
Setting up Nutanix Infrastructure
- Log into a Prism Central.
- Setup a Nutanix Kubernetes Engine (NKE) cluster with appropriate configurations For our case, we used the following configuration:
- 1x worker node with 8 vCPUs and 8 GB Memory.
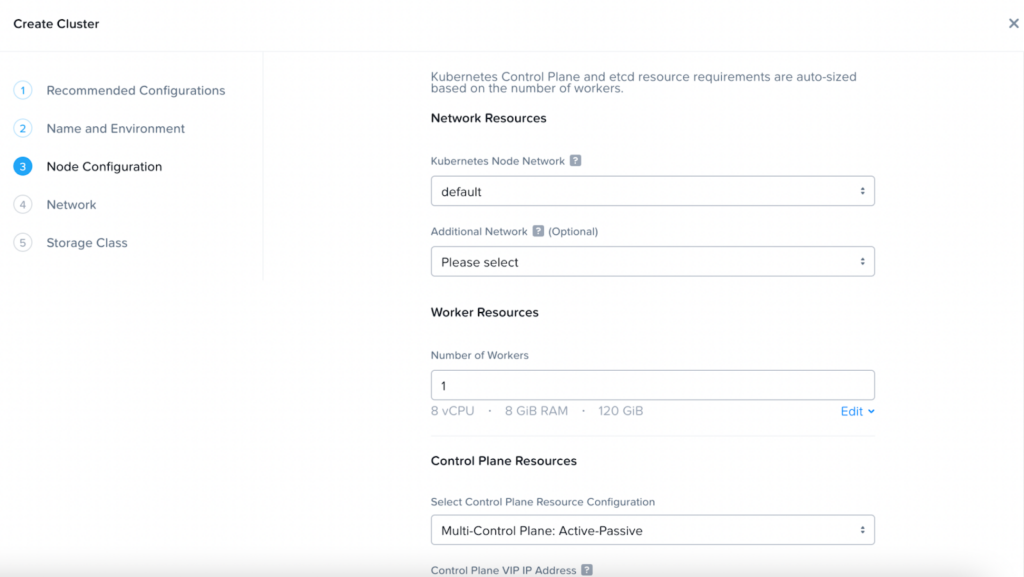
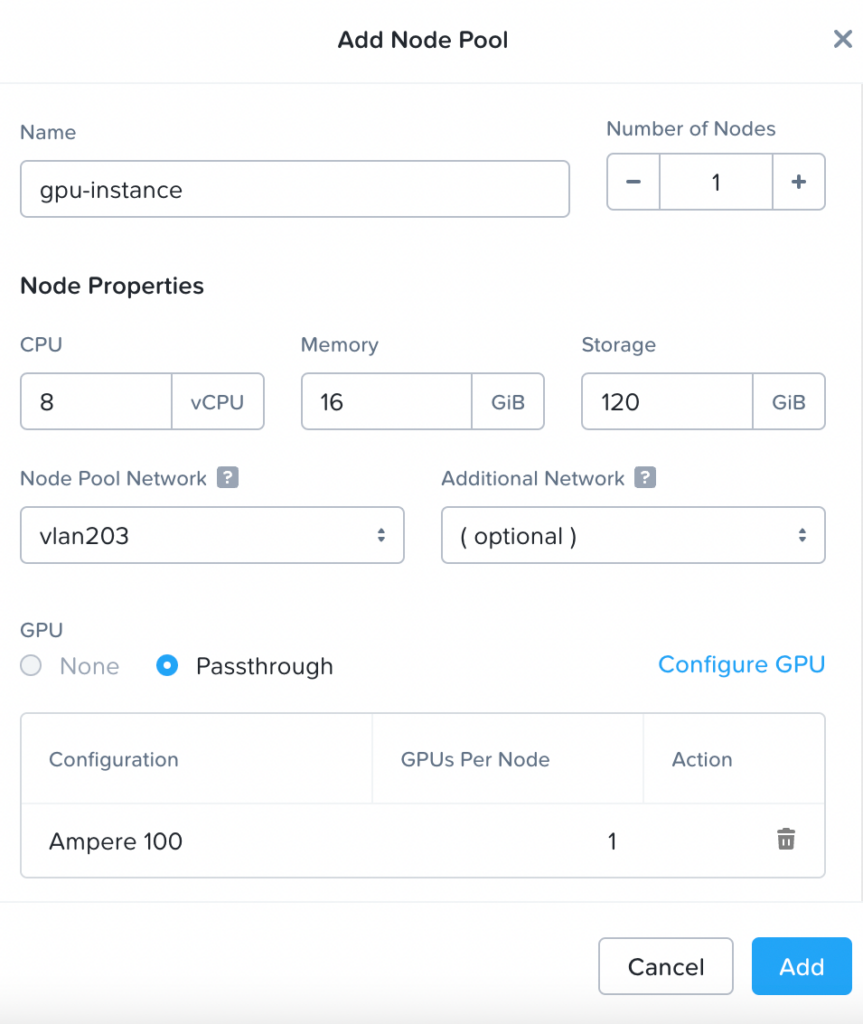
- Into the cluster we will add a GPU node with 8 vCPUs and 16 GB Memory.
- Next we install kubectl and helm. Both are required to orchestrate and set up necessary items in the NKE cluster.
- Download and set up KubeConfig by following the steps outlined in “Downloading the Kubeconfig” on the Nutanix Support Portal.
- Configure Nvidia Driver in the cluster using
helmcommands:
helm repo add nvidia https://nvidia.github.io/gpu-operator && helm repo updatehelm install --wait -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set toolkit.version=v1.13.0-centos7- Install Kserve into the cluster by executing the
curlrequest.
curl -s "https://raw.githubusercontent.com/kserve/kserve/release-0.10/hack/quick_install.sh" | bashNow we have our cluster ready for inference.
Create Stable-Diffusion inference script
Inference script will be the entry point to our model. It is responsible for loading the model and handling the inference predict request. We have to create an inference.py file and implement the model load() and predict() functions to efficiently load the model.
In addition to the inference.py file we also have to provide a requirements.txt file. The requirements.txt file is used to install the dependencies for our inference.py file.
- The first step is to create a code/ directory.
mkdir code- Next we create the
requirements.txtfile and add the following library to it.
kserve==0.10.1
torch==2.0.0
diffusers==0.3.0
transformers==4.22.1- The last step for our inference handler is to create the
inference.pyfile. In theinference.pyfile theload()function is called for the model to be loaded duringinit(). Thepredict()function is used to process the inference request.
We are using the StableDiffusionPipeline class from diffusers to load the model from HuggingFace in the load() function. The functions will be initialized inside the Text2ImageModel class inheriting from the Kserve Model class.
from typing import Dict
from kserve import Model
import base64
from timeit import default_timer as timer
from io import BytesIO
import os, sys
from datetime import timedelta
from torch import autocast
from diffusers import StableDiffusionPipeline
class Text2ImageModel(Model):
def __init__(self, name: str):
super().__init__(name)
self.name = name
self.load()
def load(self):
if os.getenv('HF_TOKEN'):
HF_TOKEN = os.getenv('HF_TOKEN')
else:
sys.exit("HF_TOKEN is empty")
model_id = "CompVis/stable-diffusion-v1-4"
self.device = os.getenv('DEVICE') or "cpu"
self.pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=HF_TOKEN)
self.pipe = self.pipe.to(self.device)
self.ready = True
def predict(self, payload: Dict) -> Dict:
overall_start = timer()
input_text = payload["instances"][0]["text"]["data"]
with autocast(self.device):
image = self.pipe(input_text, guidance_scale=7.5).images[0]
img_io = BytesIO()
image.save(img_io, 'JPEG', quality=70)
img_io.seek(0)
overall_end = timer()
result = {'image' : base64.b64encode(img_io.getvalue()).decode('utf-8') , 'time': round(timedelta(seconds=overall_end-overall_start).total_seconds(),2)}
img_io.close()
return {"predictions": result}Create Model Server using Kserve
Kserve provides ML specific template methods such as preprocess, predict, postprocess, where once you inherit those correctly, you seamlessly deploy your mode. In our example we are only made use of the predict function.
We would need to create a modelserver.py file to initialize the Text2ImageModel class and load it into the Kserve Model Server.
import os
from inference import Text2ImageModel
from kserve import ModelServer
if __name__ == "__main__":
model_name = os.getenv('MODEL_NAME') or "custom-model"
model = Text2ImageModel(model_name)
ModelServer().start([model])Containerize the ML Model
Workloads on Nutanix Kubernetes Engine (NKE) for serving ML Models need to be containerized. Dockerfile is used to create the required image.
FROM nvcr.io/nvidia/pytorch:23.01-py3
RUN apt-get update \
&& apt-get install build-essential -y \
&& apt-get clean
WORKDIR app/
COPY . ./
RUN pip install --no-cache-dir -r ./requirements.txt
CMD ["python", "modelserver.py"]With docker installed, run the docker build command to create the image and push it to a registry.
docker build -t nutanix-ai/stable-diffusion code/code/
|- Dockerfile
|- inference.py
|- modelserver.py
|- requirements.txtDeploy the image on NKE cluster
- First, we create a namespace to use for deploying KServe resources
kubectl create namespace stable-diffusion-demo- Next, define a new InferenceService YAML for the model and apply it to the cluster.
HF_TOKENis theHuggingFaceAccess Token (create one if unknown) to be used to fetch the model from the hub and the DEVICE flag is used to dictate what compute to be used for execution. Use cuda for GPU machines and cpu otherwise.
kubectl apply -n stable-diffusion-demo -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "stable-diffusion"
namespace: "stable-diffusion-demo"
annotations:
"sidecar.istio.io/inject": "false"
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m"
spec:
predictor:
maxReplicas: 1
containers:
- name: "kserve-container"
image: "nutanix-ai/stable-diffusion:latest"
env:
- name: "MODEL_NAME"
value: "stable-diffusion"
- name: "DEVICE"
value: "cuda"
- name: "HF_TOKEN"
value: "<your access token>"
resources:
requests:
memory: "7Gi"
cpu: "2"
nvidia.com/gpu: 1
limits:
memory: "7Gi"
cpu: "3"
nvidia.com/gpu: 1
EOF
- Check InferenceService status.
kubectl get inferenceservices stable-diffusion -n stable-diffusion-demo- Determine the ingress IP and ports. Depending on the use case one of the options can be followed – First Inference. For our scenario, we will use the Port Forward option.
INGRESS_GATEWAY_SERVICE=$(kubectl get svc --namespace istio-system --selector="app=istio-ingressgateway" --output jsonpath='{.items[0].metadata.name}')
kubectl port-forward --namespace istio-system svc/${INGRESS_GATEWAY_SERVICE} 8080:80- Open another terminal, and enter the following command:
export INGRESS_HOST=localhostexport INGRESS_PORT=8080Run inference on the deployed model
Once the server has loaded the required models and is up and running in our container. We can make inference requests to it. Client side requests can be from an UI or even using a simple curl request.
As we are using KServe, we should provide the request body in the KServe standardized format.
cat <<EOF > "./diffusion-input.json"
{
"instances": [
{
"text": {
"data": "An astronaut riding a horse on the beach"
}
}
]
}
EOFExport SERVICE_HOSTNAME and execute the curl request.
SERVICE_HOSTNAME=$(kubectl get inferenceservice stable-diffusion -n stable-diffusion-demo -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v -H "Host: ${SERVICE_HOSTNAME}" "http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/sklearn-iris:predict" -d @./diffusion-input.jsonThe request provides the following output.

Have fun trying out more such examples and be amazed at the power of Machine Learning.
Conclusion
In this article, we have shown how easy it is to use the Nutanix Cloud Platform to deploy the state of the art generative AI models. NCP allows customers to achieve consistency across their entire infrastructure stack, from edge to the cloud for both the data lifecycle and the MLOps needs of the organization.