

Summary
Large Language Models (LLMs) based on the transformer architecture (for example, GPT, T5, and BERT) have achieved state-of-the-art (SOTA) results in various Natural Language Processing (NLP) tasks such as multi-language understanding (GPT-4 achieving MMLU score of 86.4), logical interpretations (PaLM-2-L achieving BBH score of 65.7), multi-step mathematical reasoning (GPT-4 achieving GSM8K of 92.0), reading comprehension (PaLM-2-L scoring 86.1 in TriviaQA), and question answering (PaLM-2-L scoring 37.5 in Natural Questions). Currently, there are hundreds of pre-trained LLM models with new models coming up frequently. These models have fine-grained details in terms of architectures, token sizes, data lineages, context lengths, parameter counts, number of layers, model dimensionality, attention head counts, training languages, benchmarking details, and so on. In fact, it is intimidating to enterprise users to choose from a large variety of pre-trained LLM models. As we interact with several enterprise customers and our partners, we often encounter this question: what are the good LLM models and can Nutanix Cloud infrastructure (NCI) support them? This article discusses some of the prominent pre-trained LLM models available–either open source or proprietary-and their common use cases. We also present a benchmarking study evaluating the inference latency of different models on a given configuration of Nutanix Cloud Platform (NCP).
Pre-Training of Large Language Models
The large language model has truly captured the popular media which is abuzz with jargons and catchphrases. This section aims to inform what is pre-training in the context of a large language model, and how it is different from other functional phases such as supervised finetuning and RLHF, as shown in Figure 1.
The pre-training deals with developing a self-supervised learning model from a large corpus of data. A pre-trained model takes text (a prompt) and generates text (a completion), Figure 2.

Large language models are auto-regressive in nature. They typically use decoder-only transformer models for self-supervised learning. Supervised finetuning and RLHF are used for adapting pre-trained LLMs to domain-specific tasks such as summarization and question answering.
List of Pre-Trained Large Language Models
Table 1 shows a list of 14 different pre-trained LLMs and their parameter counts, use cases, and managing organizations. It shows the parameter counts roughly vary between 1.7T (an unofficial estimate for GPT-4) to 11B (FLAN-t5-xxl). The use cases include conversational interfaces such as chatbots, question-answering, logical/mathematical reasoning, and summarization. These models come both from corporate research labs (such as OpenAI) and open source projects (such as Open Assistant). The model parameters are determined by embedding dimensions, number of attention heads, number of layers, dimensionality of keys and values, and dropout rates.
| Model | Parameter Count | Use Case | Org. |
|---|---|---|---|
| LLaMA-2 | 70B | chatbots, question-answering, math | Meta |
| GPT-4 | 1.7T1 | chatbots, AI system conversations, and virtual assistants | OpenAI |
| GPT-3 | 175B | create human-like text and content (images, music, and more), and answer questions in a conversational manner | OpenAI |
| Codex | 12B | programming, writing, and data analysis | OpenAI |
| Claude-V1 | 52B | research, creative writing, collaborative writing, Q&A, coding, summarization | Anthropic |
| Bloom | 176B | text generation, exploring characteristics of language generated by a language model | BigScience |
| FLAN-t5-xxl | 11B | research on language models | |
| Open-Assistant SFT-4 12B | 12B | as an assistant, such that it responds to user queries with helpful answers | Open Assistant Project |
| SantaCoder | 1.1B | multilingual large language model for code generation | BigCode |
| PaLM 2 | 340 N | common sense reasoning, formal logic, mathematics, and advanced coding in 20+ languages | |
| Gopher | 280B | reading comprehension, fact-checking, understanding toxic language, and logical and common sense tasks | DeepMind |
| Falcon | 40B | commercial uses, chatting | TII |
| Vicuna | 33B | chatbots, research, hobby use | LMSYS |
| MPT | 33B | reading and writing related use cases | MosaicML |
| ERNIE 3.0 Titan | 260B | chatbot | Baidu |
Inference Benchmarking of Open Source LLMs on Nutanix Cloud Platform
In this section, we present an inference benchmarking study of different open source LLMs with Apache2.0 license on Nutanix Cloud Platform (NCP).
Configuration of Nutanix Cloud Platform
With Nutanix Cloud Platform, Nutanix delivers the simplicity and agility of a public cloud alongside the performance, security, and control of a private cloud. At Nutanix, we are dedicated to enabling customers with the ability to build and deploy intelligent applications anywhere—edge, core data centers, service provider infrastructure, and public clouds. We offer a zero-touch AI infrastructure which reduces the infrastructure configuration and maintenance burden on machine learning scientists and data engineers. Prism Element (PE) is a service built into the platform for every Nutanix cluster deployed. Prism Element enables a user to fully configure, manage, and monitor Nutanix clusters running any hypervisor. Therefore, the first step of the Nutanix infrastructure setup is to log into a Prism Element, as shown in Figure 3.
Log into Prism Element on a Cluster (UI shown in Figure 3)
VM Configuration
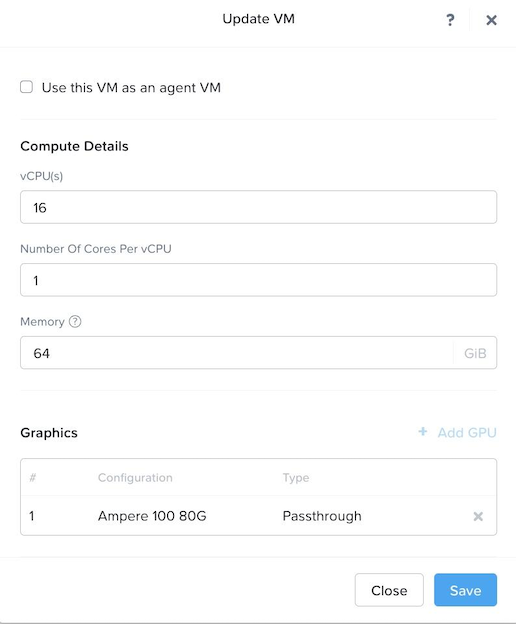
After logging into Prism Element2, we create a VM hosted on our Nutanix AHV cluster. As shown in Figure 4, the VM has following resource configuration settings: 22.04 Ubuntu operating system, 16 single core vCPUs, 64 GB of RAM, and NVIDIA A100 Tensor Core passthrough GPU with 80GB memory. The GPU is installed with the NVIDIA RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run). The large deep learning models with transformer architecture require GPU or other compute accelerators with high memory bandwidth, large registers and L1 memory.
Underlying A100 GPU
NVIDIA A100 Tensor Core GPU is designed to power the world’s highest-performing elastic data centers for AI, data analytics, and HPC. Powered by the NVIDIA Ampere Architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands. To peek into the detailed features of A100 GPU, we run `nvidia-smi` command which is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. The output of the `nvidia-smi` command is shown in Figure 5. It shows the Driver Version to be 515.86.01 and CUDA version to be 11.7.
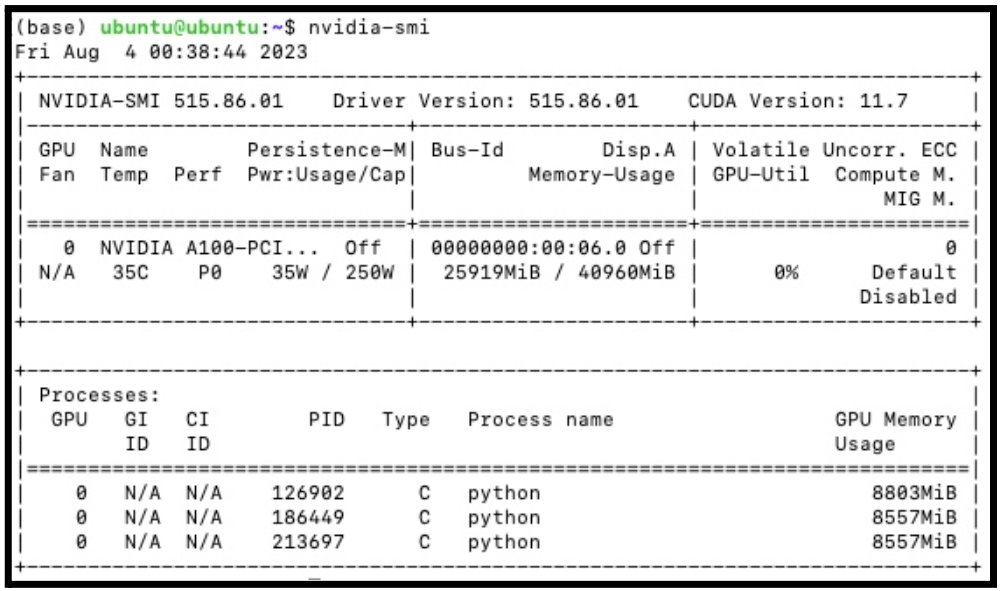
Table 2 shows several key features of the A100 GPU we used.
| Feature | Value | Description |
|---|---|---|
| GPU | 0 | GPU Index |
| Name | NVIDIA A100 | GPU Name |
| Temp | 35 C | Core GPU Temperature |
| Perf | P0 | GPU Performance |
| Persistence-M | On | Persistence Mode |
| Pwr: Usage/Cap | 65 W / 300 W | GPU Power Usage and it capability |
| Bus Id | 00000000:00:06.0 | domain:bus:device.function |
| Disp. A | Off | Display Active |
| Memory-Usage | 25919MiB / 40960MiB | Memory allocation out of total memory |
| Volatile Uncorr. ECC | 0 | Counter of uncorrectable ECC memory error |
| GPU-Util | 0% | GPU Utilization |
| Compute M. | Default | Compute Mode |
| MIG M. | Disabled | Multi-Instance Mode |
Benchmarking Results
We have conducted our benchmarking study on 16 different open source models with Apache 2.0 license. All these models were tested with a common prompt: “Generative AI is “ and context window size of 50. Table 3 shows different open source LLMs and parameter counts.
Latency Benchmarking
Table 4 shows the mean inference (response generation to the prompt) time and its standard error across 3 independent runs for 16 different models. It is expected that the smaller models have lower inference time. We see it is indeed the case with the smallest 5B model “aisquared/dlite-v2-1_5b” to have lowest inference time of 22.87 +/- 0.51 s (across three different runs). However, counterintuitively, mosaicml/mpt-7b with 7B model parameters seems to have the largest generation time of 130.79 +/- 4.31 s. It could be because of the model architecture. We have also noted that the four larger models (“google/flan-ul2”, “cerebras/Cerebras-GPT-13B”, “databricks/dolly-v2-12b”, “openlm-research/open_llama_13b”) fails to produce any response because of the limited GPU memory of ~25GB. It is quite expected for 16-bit precision.
| Models | Mean Time (s) | Std. Error (s) |
|---|---|---|
| google/flan-ul2 | Fail | Fail |
| cerebras/Cerebras-GPT-13B | Fail | Fail |
| cerebras/Cerebras-GPT-6.7B | 105.11 | 1.60 |
| OpenAssistant/oasst-sft-1-pythia-12b | 114.09 | 0.20 |
| EleutherAI/pythia-12b | 113.92 | 0.26 |
| EleutherAI/gpt-j-6b | 87.64 | 5.17 |
| databricks/dolly-v2-12b | Fail | Fail |
| aisquared/dlite-v2-1_5b | 22.87 | 0.51 |
| EleutherAI/gpt-j-6b | 90.48 | 3.69 |
| mosaicml/mpt-7b | 130.79 | 4.31 |
| RedPajama-INCITE-Base-3B-v1 | 26.66 | 1.50 |
| RedPajama-INCITE-7B-Base | 60.23 | 0.91 |
| tiiuae/falcon-7b | 104.40 | 4.56 |
| h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3 | 101.73 | 4.04 |
| openlm-research/open_llama_7b | 60.59 | 2.07 |
| openlm-research/open_llama_13b | Fail | Fail |
Accuracy Benchmarking
Table 5 shows the responses from 16 different models to a given prompt, “Generative AI is “ and their accuracy assessments. We set the output token size cut-off to be 50. We see acceptable results from models such as “OpenAssistant/oasst-sft-1-pythia-12b”, “tiiuae/falcon-7b”, “h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3”, “RedPajama-INCITE-Base-3B-v1”, “RedPajama-INCITE-7B-Base”. The remaining models either hallucinate (meaning irrelevant response) or produce partially accurate results. In general, the modes with large parameter counts perform better. In that context, “RedPajama-INCITE-Base-3B-v1”, “RedPajama-INCITE-7B-Base”, “tiiuae/falcon-7b”, “h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3” perform impressively even though they have sub-10B parameter counts. Although “mosaicml/mpt-7b” has the highest response time, it does not exhibit good accuracy.
| Models | Response to the Prompt: “Generative AI is “ | Accuracy Estimate |
|---|---|---|
| google/flan-ul2 | Fail | Fail |
| cerebras/Cerebras-GPT-13B | Fail | Fail |
| cerebras/Cerebras-GPT-6.7B | Generative AI is \na field that’s been around for a while, but it’s only recently that it has been really taken seriously. It’s a field that is, in many | Partially accurate but not precise |
| OpenAssistant/oasst-sft-1-pythia-12b | Generative AI is \na subfield of machine learning that uses algorithms to generate new data based on patterns found in existing data. It is a type of artificial intelligence that is designed to create novel and diverse outputs that are not explicitly programmed. | Excellent |
| EleutherAI/pythia-12b | Generative AI is \nthe idea that we can create a computer program that can learn to do things that ive never seen before.\nSo, for example, if you give it a bunch of pictures of cats, it can start to learn | Vague |
| EleutherAI/gpt-j-6b | Generative AI is \na field of computer science that is concerned with the creation of intelligent machines.\n\nGeneration of AI\nThe generation of artificial intelligence is the process of creating a computer program that can perform tasks that are similar to those | Poor |
| databricks/dolly-v2-12b | Fail | Fail |
| aisquared/dlite-v2-1_5b | Generative AI is \n\nA type of AI that can generate its own solutions to problems.\nIt is a form of artificial intelligence that uses a large amount of data and a lot of training data to train a model to a solution. It | Not Precise |
| EleutherAI/gpt-j-6b | Generative AI is \na field of computer science that is concerned with the creation of intelligent machines.\n\nGeneration of AI\nThe generation of artificial intelligence is the process of creating a computer program that can perform tasks that are similar to those | Poor |
| mosaicml/mpt-7b | Generative AI is icing on the cake for the future of work\nBy: David Cearley\nThe future is here. It’s just not evenly distributed.\nIn the past few years, we’ve seen the rise of the | Hallucination |
| RedPajama-INCITE-Base-3B-v1 | Generative AI is \nthe ability to generate new data from a given dataset.\n\n\\subsection{Generating Data}\nGenerators are the core component of generative models. \n\n\n\nA generator is a function that takes a | Very Good |
| RedPajama-INCITE-7B-Base | Generative AI is \ngenerating new content, and it’s not just text.\n\n## Generative Art\nGenerating art is a popular use case for generative models. \xa0The most popular generatives for art are | Very Good |
| tiiuae/falcon-7b | Generative AI is “the ability of a computer program to automatically generate new data, such as text, images, or videos, that are similar to existing data.”\nThe term ‘generative’ refers to the ability to create new content | Excellent |
| h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3 | Generative AI is “a type of artificial intelligence that is capable of generating new data, rather than just processing and analyzing existing data.”\nIn other words, it’s a type AI that can create new information, not just process and analyze | Excellent |
| openlm-research/open_llama_7b | Generative AI is 100% free to use.\nThe best part is that you can use it to create your own custom avatars, and even use them in your games. You can also use the avatar generator to make | Not Precise |
| openlm-research/open_llama_13b | Fail | Fail |
Conclusion
In this article, we demonstrate how we can use the Nutanix Cloud Platform for inference benchmarking of open source LLMs with Apache 2.0 license. We cover 16 different models in this article. For reproducibility, we are releasing the underlying code: Git Repo.
Moving Forward
This is the seventh blog on the topic of AI readiness of Nutanix. The previous blogs can be found here: Link. In the future, we are planning to publish articles on foundation models, RLHF, and instruction tuning.
Acknowledgement
The authors would like to acknowledge the contribution of Johnu George, Staff Engineer at Nutanix.
Footnotes
- an unofficial estimate
- A third-party user would need to interface with Prism Central to log into Prism Element running on a cluster with an appropriate role-based access control (RBAC) credential.