

Introduction
The goal of this article is to show how customers can develop a generative pre-trained transformer (GPT) model from scratch using open source Python® libraries on the Nutanix Cloud Platform™ (NCP) full-stack LLM infrastructure platform.
We largely adopted the model architecture from GPT-2 paper with 1.5B parameters and built a miniaturized GPT model with 11M parameters. In this article, the model has been trained with the wikitext-2-raw dataset. It crawls over 23M URLs and over 10M HTML pages. Pre-trained models, such as the GPT-2, GPT-3, PaLM, Llama-2, and BloombergGPT models, serve as a foundation for sophisticated LLMs performing various NLP tasks such as question answering, summarization, machine translation, code generation, sentiment analysis, named entity detection, text entailment, commonsense reasoning, and reading comprehension.
We presume that a deep understanding of pre-trained model training leads to better decision-making for LLM system design, including model sizing, dataset sizing, and compute infrastructure provisioning. Some customers might need to train a pre-trained model from the ground up because their datasets are very different from datasets like C4, which are used to train popular pre-trained models such as GPT-3 and Llama-2.
The compute infrastructure provisioning for LLM pre-training can be a complex endeavor, especially in consideration of data privacy, data sovereignty and data governance. The breakneck speed of AI innovation around model and training dataset availability and compute optimization trigger rapid enterprise AI adoption. This gold rush of enterprise AI adoption demands infrastructure solutions that can scale easily, securely and robustly with teams trained to manage more traditional workloads. In this article, we show how NCP can be leveraged to train GPT-2 or bigger models with WebText or a similar dataset.
LLM Pre-Training
LLM Pre-training typically involves heavily over-parameterized and decoder-only transformers as the base architecture and model natural language in bidirectional, autoregressive or sequence-to-sequence manners on large-scale unsupervised corpora.
The premise of the GPT-2 model is a high-capacity, self-supervised, and generative model trained on a dataset with sufficiently large volume and variety, and can perform multiple tasks simultaneously with minimal discriminative supervision in the form of fine-tuning and in-context learning.
The generative capability of some of the pre-trained, high-capacity models, such as GPT-4 and PaLM, are so good that they obviate the need for downstream discriminative supervision. Due to its autoregressive nature, pre-trained models are most adept in text generation and fill mask tasks.
The large language model has truly captured the popular media, which is abuzz with jargons and catchphrases. This section aims to inform what is pre-training in the context of a large language model, and how it is different from other functional phases, such as supervised finetuning and reinforcement learning on human feedback (RLHF), as shown in Figure 1.
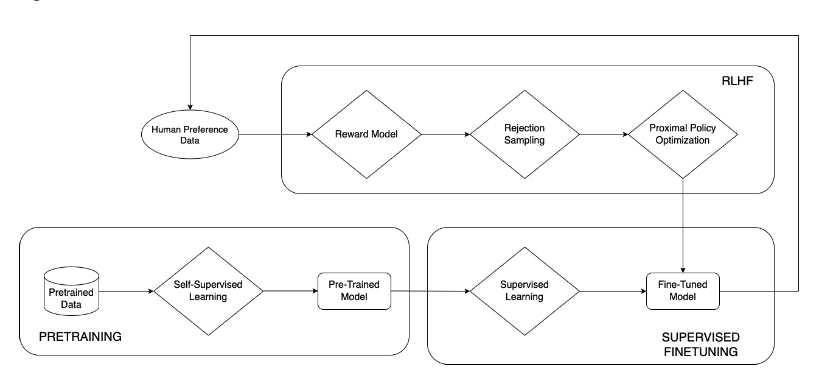
The pre-training deals with developing a self-supervised learning model from a large corpus of data. A pre-trained model takes text (a prompt) and generates text (a completion), as shown in Figure 2.
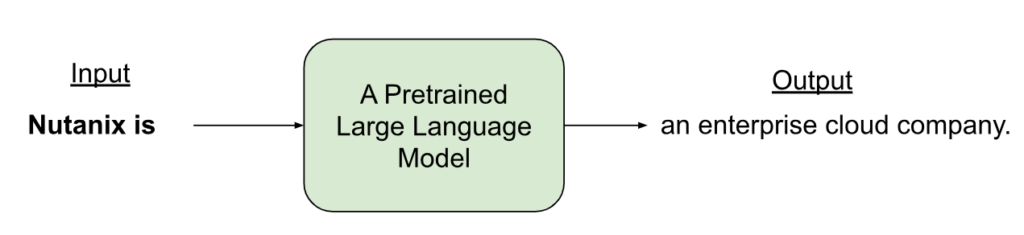
Large language models are autoregressive in nature. They typically use decoder-only transformer models for self-supervised learning. Supervised finetuning and RLHF are used for adapting pre-trained LLMs to domain-specific tasks such as summarization and question answering.
AI in Nutanix Infrastructure Stack
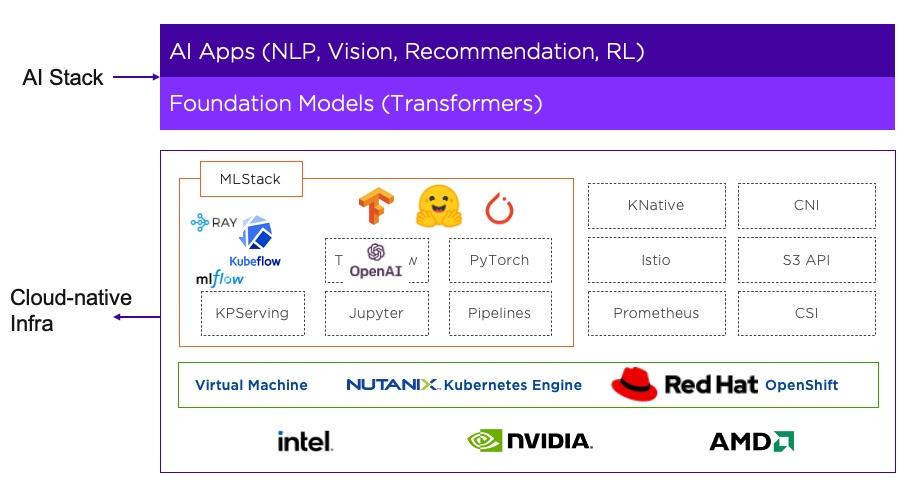
Figure 3 shows how AI/ML is integrated into the core Nutanix® infrastructure layer. The foundation models are essentially pre-trained generative models, such as BERT, GPT-3 and DALL-E. They assume a central role in this integration. The foundation models, a.k.a. the pre-trained models, run on the cloud-native infrastructure stack of NCP and empower customers to build a wide array of generative AI apps.
Setting up NCP for GPT Model Pre-Training
At Nutanix, we are dedicated to enabling customers to build and deploy intelligent applications anywhere—edge, core datacenters, service provider infrastructure, and public clouds. The Prism Element™ management console enables users to fully configure, manage and monitor Nutanix clusters running any hypervisor. Therefore, the first step of the Nutanix infrastructure setup is to log into a Prism Element, as shown in Figure 4.
- Log into a Prism Element (the UI is shown in Figure 4)
- Set up the Virtual Machine
After logging into Prism Element, we create a virtual machine (VM) hosted on our Nutanix AHV® cluster. As shown in Figure 5, the VM has following resource configuration settings: 22.04 Ubuntu® operating system, 16 single core vCPUs, 64 GB of RAM, and NVIDIA® A100 tensor core passthrough GPU with 40 GB memory. The GPU is installed with the NVIDIA RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run). The large deep learning models with transformer architecture require GPU or other compute accelerators with high memory bandwidth, large registers and L1 memory.
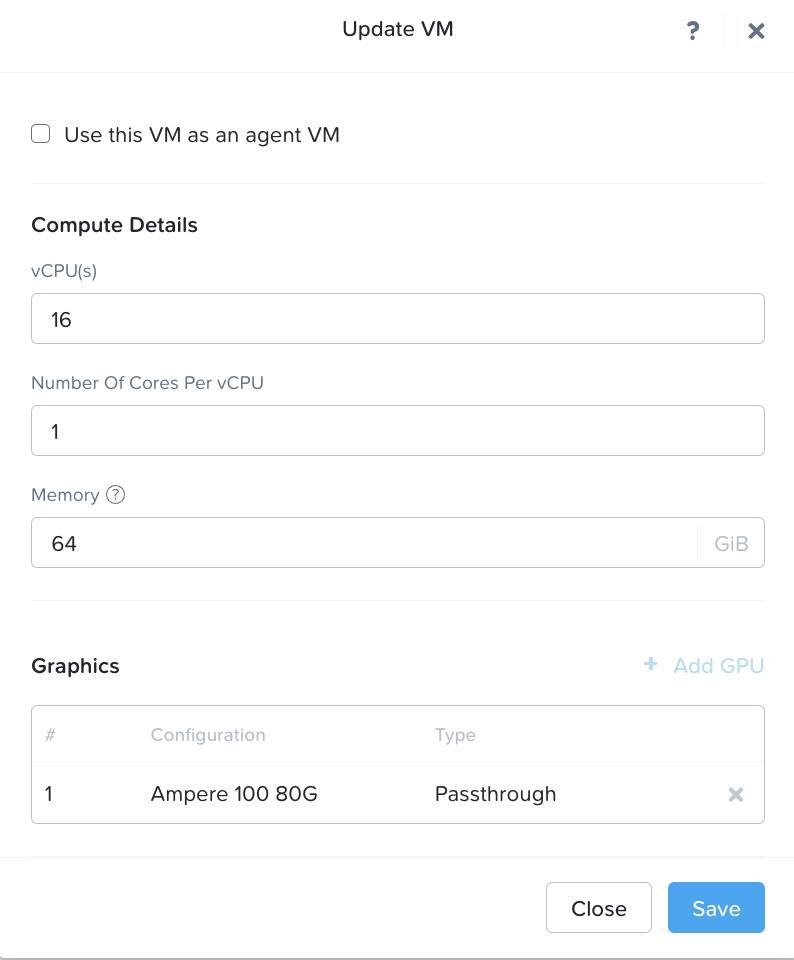
- Underlying A100 GPU
The NVIDIA A100 Tensor Core GPU is designed to power the world’s highest-performing elastic datacenters for AI, data analytics, and HPC. Powered by the NVIDIA Ampere™ architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands.
The A100 80GB debuts the world’s fastest memory bandwidth at over 2 terabytes per second (TB/s) to run the largest models and datasets. To peek into the detailed features of A100 GPU, we run `nvidia-smi` command which is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. The output of the `nvidia-smi` command is shown in Figure 6. It shows the Driver Version to be 515.86.01 and CUDA version to be 11.7.
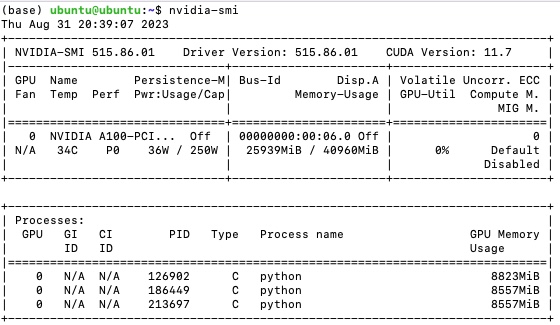
Figure 6 shows several critical features of the A100 GPU we used. The details of these features are described in Table 1.
| Feature | Value | Description |
|---|---|---|
| GPU | 0 | GPU Index |
| Name | NVIDIA A100 | GPU Name |
| Temp | 34 C | Core GPU Temperature |
| Perf | P0 | GPU Performance |
| Persistence-M | On | Persistence Mode |
| Pwr: Usage/Cap | 36W / 250W | GPU Power Usage and it capability |
| Bus Id | 00000000:00:06.0 | domain:bus:device.function |
| Disp. A | Off | Display Active |
| Memory-Usage | 25939MiB / 40960MiB | Memory allocation out of total memory |
| Volatile Uncorr. ECC | 0 | Counter of uncorrectable ECC memory error |
| GPU-Util | 0% | GPU Utilization |
| Compute M. | Default | Compute Mode |
| MIG M. | Disabled | Multi-Instance Mode |
GPU Pre-Training on Nutanix Cloud Platform
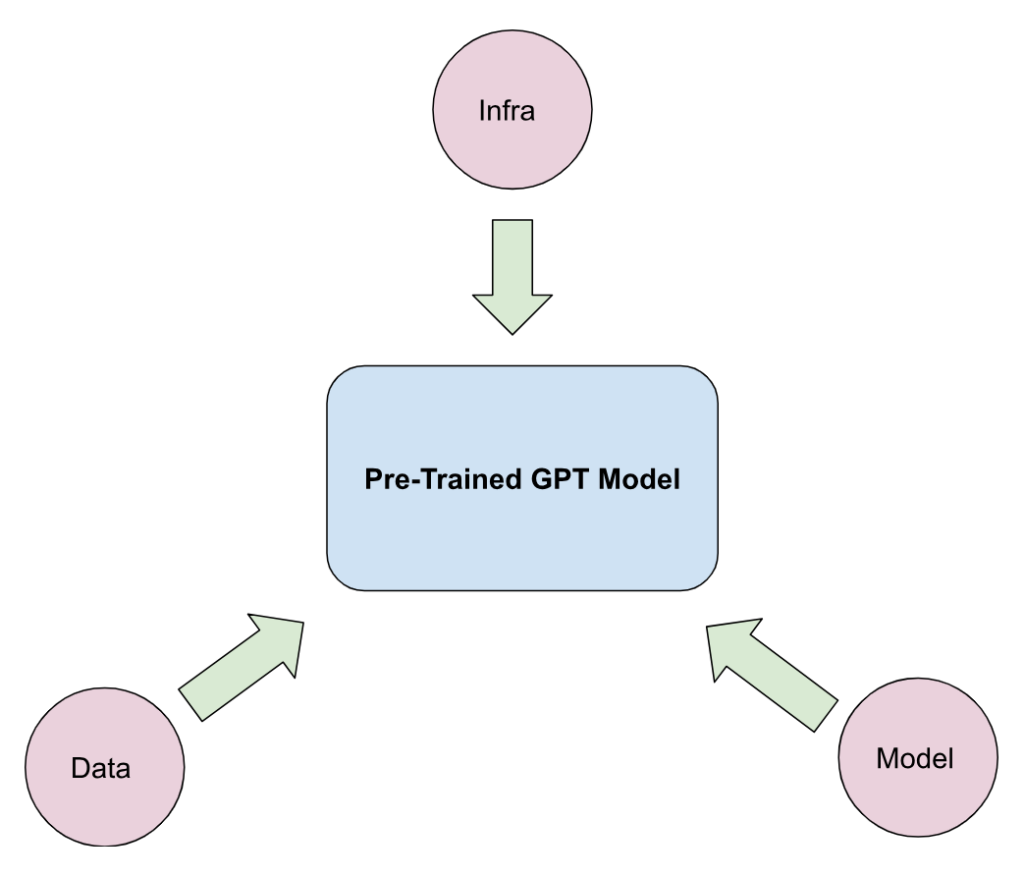
The development of a pre-trained GPT model has three different artifacts: Data, model and infrastructure. The infrastructure piece was described in the last section. We have used the wikitext-2-raw dataset. It crawls over 23M URLs and over 10M HTML pages. We used a Transformer-based architecture similar to GPT-2.
Code Walkthrough
This section walks through the implementation details of the GPT. The pertinent codebase can be found in this repo. The repo has the following directory structure:
├── LICENSE
├── README.md
├── configurator.py
├── data
│ ├── data
│ │ └── input.txt
│ └── prepare.py
├── model.py
├── requirements.txt
├── sample.py
└── train.py
| File | Description |
|---|---|
| LICENSE | Apache 2.0 License |
| README.md | Readme markdown |
| configurator.py | Configuration file |
| data/data/input.txt | Input text file |
| model.py | Outline model-specific details |
| data/data/prepare.py | Prepare dataset |
| requirements.txt | Declare required Python libraries |
| sample.py | Trigger output |
| train.py | Run training |
Data Engineering
We use a multilingual wikitext-2-raw dataset with a vocabulary size of 1,013 with 10,918,892 characters. The relevant data engineering code can be found in `prepare.py` script and run with `python prepare.py` command. This splits the dataset into training and validation tokens stored in a train.bin and val.bin in that data directory. The training set has 9,827,002 tokens and the validation set has 1,091,890 tokens.
Model Training Details
Table 3 shows the details of different model and training parameters for this article. Due to the limited computational resources, the model used was of significant low capacity of 11M parameters.
| Parameter | Specifications |
|---|---|
| batch size | 32 |
| block_size or context window | 256 |
| number of Transformer layers | 6 |
| number of attention head | 6 |
| embedding dimension | 384 |
| dropout | 0.2 |
| learning rate | 1e-3 |
| weight decay | 1e-1 |
| max iterations | 5000 |
| learning rate decay iteration | 5000 |
| minimum learning rate | 1e-4 |
| beta1 | 0.9 |
| beta2 | 0.99 |
| grad clip | 0.1 |
| Warmup iterations | 100 |
| Loss Function | Cross Entropy |
Results
| Summary Statistic | Final Value |
| Iterations | 5000 |
| Learning Rate | 0.0001 |
| Model Flops Utilization (MFU) | 13.23778 |
| Training loss | 1.21256 |
| Validation loss | 1.31918 |

Figure 9 shows the output from the GPT model with the training data. It shows reasonable validation accuracy. It generates 500 tokens in each sample and retains the top 200 tokens.
Key Takeaways
- We trained a miniaturized GPT model with 11M parameters on wikitext-2-raw dataset. The model has similar architecture to GPT-2.
- The model shows reasonably good cross-entropy loss of 1.31918 on validation dataset.
Next Steps
We have focused on LLM pre-training in the blog. Previously, we have covered LLM fine-tuning. Our future blogs will explore the following topics:
Acknowledgement
The authors would like to acknowledge the contribution of Johnu George, staff engineer at Nutanix.
© 2023 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.
This post may contain express and implied forward-looking statements, which are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances