

Introduction
The goal of this article is to show how customers can use a reinforcement learning on human feedback (RLHF) workflow to finetune a large language model (LLM) from scratch using open source Python® libraries on the Nutanix Cloud Platform™ (NCP) HCI solution. RLHF is increasingly being used over vanilla supervised finetuning or instruction tuning because of its ability to generalize better for dynamic datasets with frequent distribution shifts. Most chat models such as “meta-llama/Llama-2-70b-chat” use RLHF for downstream task-specific adaptation. We presume that a deep understanding of RLHF aids in better decision-making for LLM downstream task adaptation. In general, RLHF with proximal policy optimization (PPO) is the key technique used in the ChatGPT™, Anthropic™, and Llama™ Chat models for downstream adaptation. Essentially, RLHF replaces static finetuning data with human feedback which is often more intuitive to generate and captures real human assessment on helpfulness and safety. The compute infrastructure provisioning for RLHF can be a complex endeavor, especially in consideration of data privacy, data sovereignty and data governance. The breakneck speed of AI innovation around model and training dataset availability and compute optimization trigger rapid enterprise AI adoption. This gold rush of enterprise AI adoption demands infrastructure solutions that can scale easily, securely and robustly with teams trained to manage more traditional workloads. In this article, we show how NCP can be leveraged to perform RLHF workflow on a GPT-2 based policy network and Bert based reward network on IMDB dataset. We validate that RLHF tunes the policy network and thereby improves the average positive sentiment score of the output from the policy network by a significant margin.
RLHF Workflow
The goal of RLHF is to alter the behavior of a supervised policy, essentially a LLM model in this context, based on human feedback. Based on their preferences, human annotators assign their valuations to LLM predictions. RLHF essentially imposes the human preferences to tune the LLM parameters to adapt to human preferences. Reinforcement learning deals with a goal-seeking agent interacting with an environment to maximize a long-term cumulative reward score by choosing appropriate actions. In RLHF, the role of an RL agent is played by a policy optimization algorithm such as PPO which tunes the behavior of an LLM model by updating its parameters. The role of the environment is played by a reward network built on a compilation of human feedback. Figure 1 shows a schematic representation of an RLHF workflow.
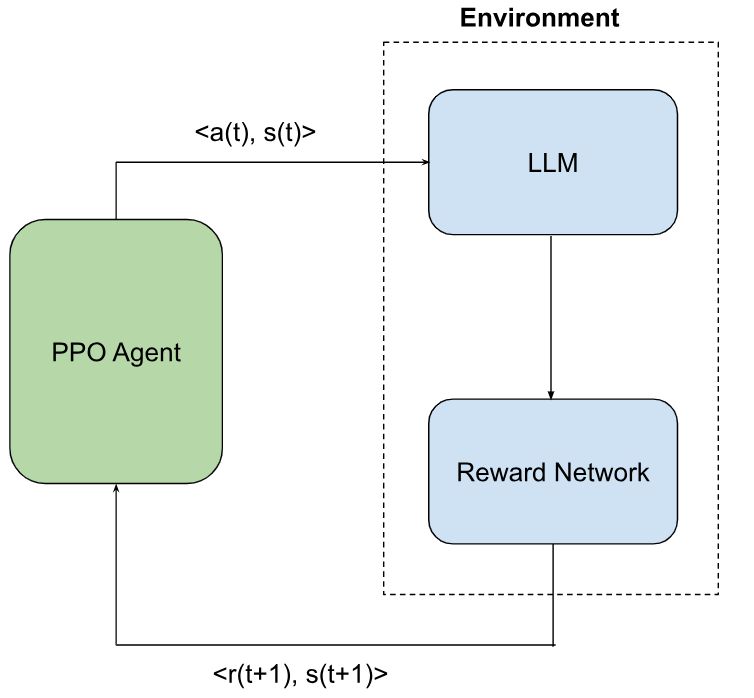
An RLHF workflow involves following steps.
- Collect demonstration data and train a supervised policy
- Compile a collection of (sample, desired response) pairs
- Fine tune a pre-trained model such as GPT-3.5 or Llama-7b.
In most enterprise use cases, a pre-trained or supervised fine-tuned model is selected.
- Collect comparison data and train a reward model
- Compile a prompt and several model outputs
- Annotators ranks the outputs from best to worst
- Train a reward model based on the augmented data with human preferences
- Optimize a policy against the reward model using the PPO-based RL algorithm. This is essentially the RLHF loop.
- A new prompt is sampled from the dataset
- The PPO model is initialized from the supervised policy
- The policy generates an output
- The reward model calculates a reward for the output
- The reward is used to update the policy using PPO
This article walks through the implementation of these different steps from scratch. Before jumping into the implementation, we will discuss the Nutanix infrastructure stack for running the AI workloads. In an RLHF workflow, PPO plays the central role of a learning algorithm. PPO is an on-policy learning algorithm. It means as it explores by sampling actions according to the latest version of the policy. The discrete action space for the PPO consists of a ranking of different answers generated by the LLM. On the other hand, the usual state space of PPO consists of billions of LLM model parameters.
Nutanix Cloud Platform
At Nutanix, we are dedicated to enabling customers to build and deploy intelligent applications anywhere – edge, core data centers, service provider infrastructure, and public clouds. Figure 2 shows how AI/ML is integrated into the core Nutanix® infrastructure layer. RLHF is a key workflow in the development of AI Applications at the top.
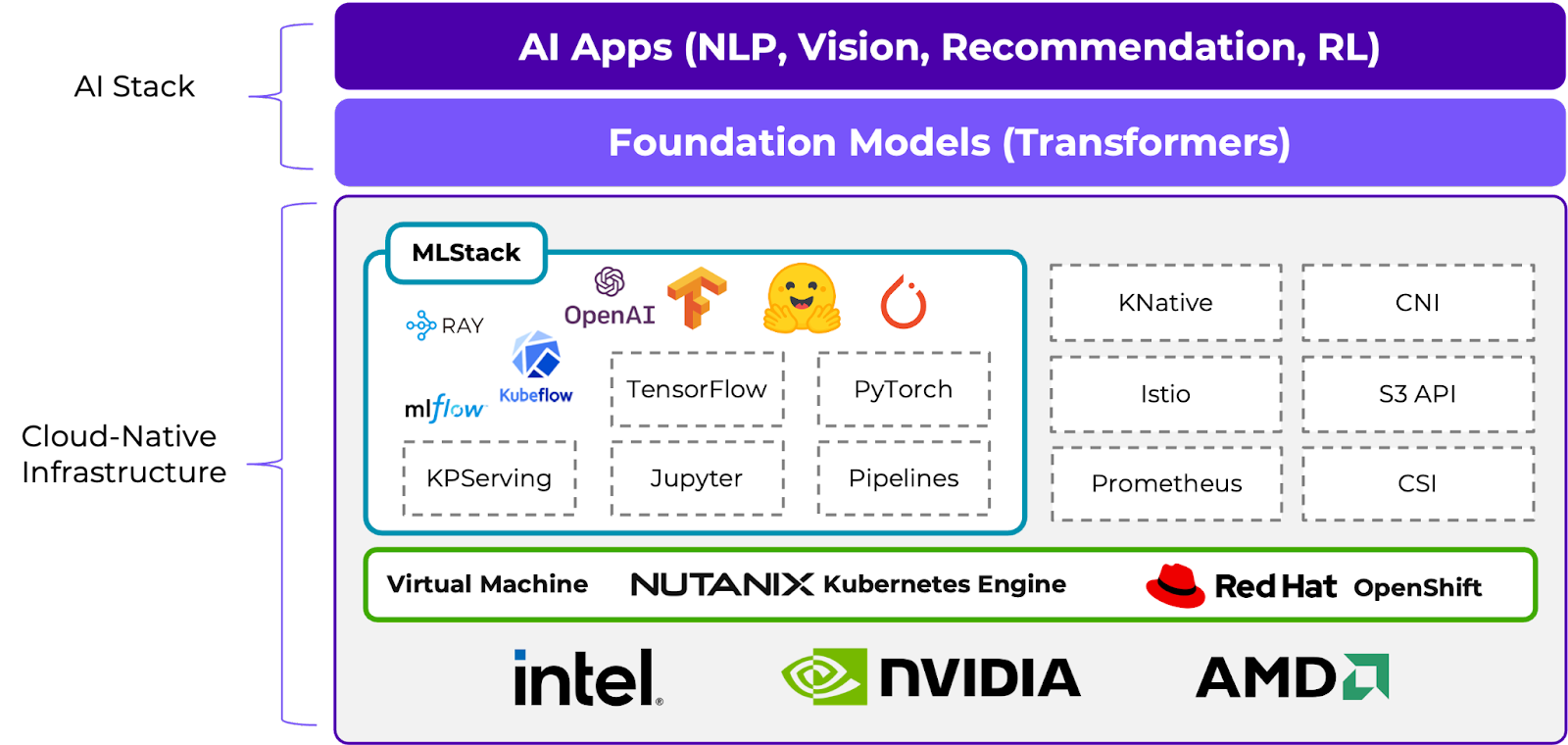
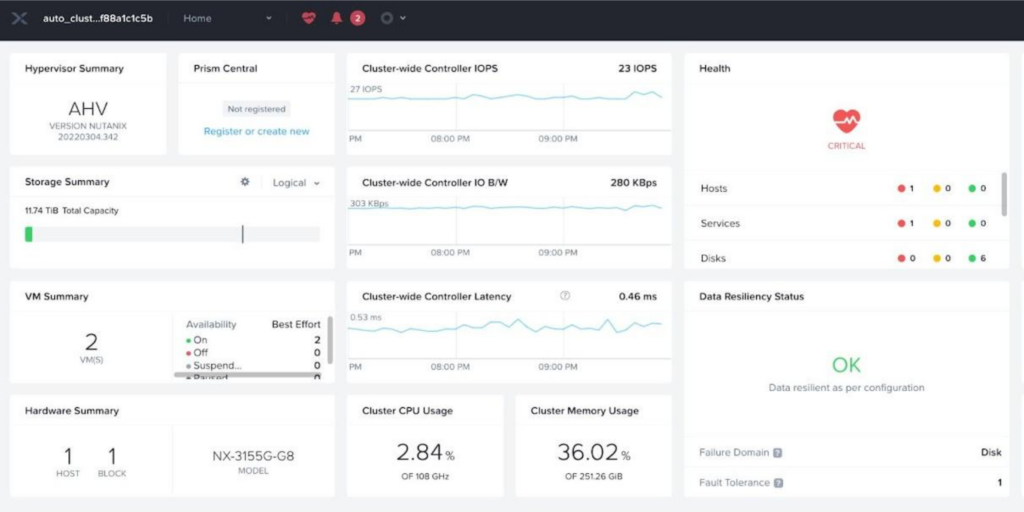
As shown in Figure 2, the App layer runs on the top of the infrastructure layer. The infrastructure layer can be deployed in two steps, starting with Prism Element™ login followed by VM resource configuration. Figure 3 shows the UI for Prism Element.
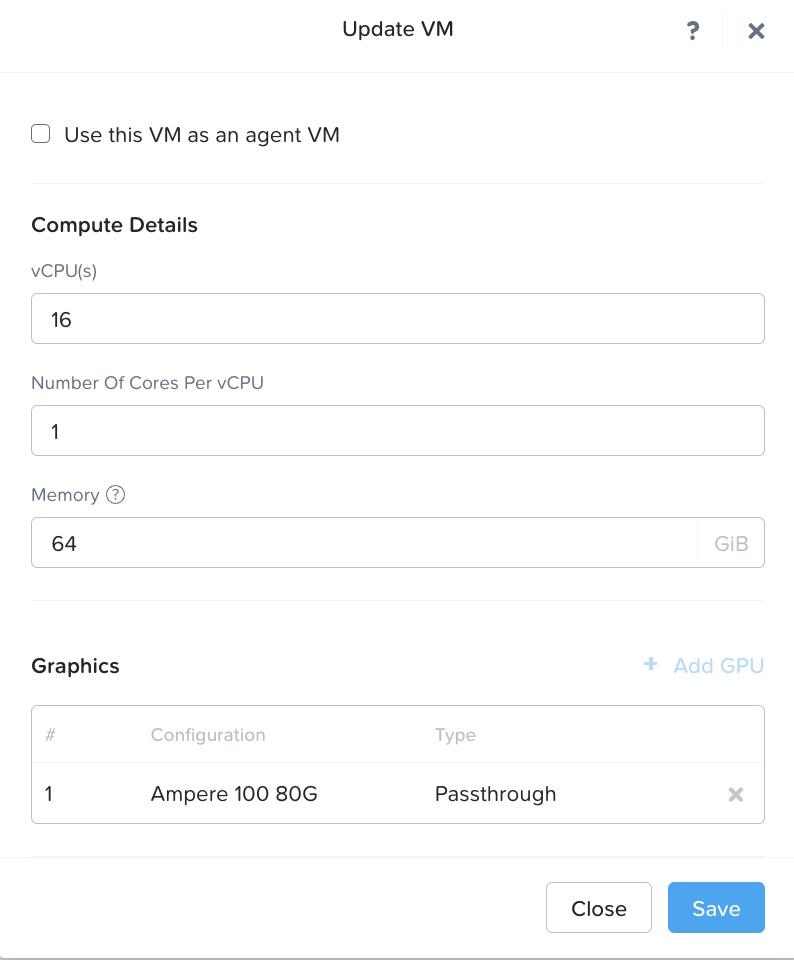
After logging into Prism Element, we create a virtual machine (VM) hosted on our Nutanix AHV® cluster. As shown in Figure 4, the VM has following resource configuration settings: 22.04 Ubuntu® operating system, 16 single core vCPUs, 64 GB of RAM, and NVIDIA® A100 tensor core passthrough GPU with 40 GB memory. The GPU is installed with the NVIDIA RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run). The large deep learning models with transformer architecture require GPU or other compute accelerators with high memory bandwidth, large registers and L1 memory.
The NVIDIA A100 Tensor Core GPU is designed to power the world’s highest-performing elastic datacenters for AI, data analytics, and HPC. Powered by the NVIDIA Ampere™ architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands.
To peek into the detailed features of A100 GPU, we run `nvidia-smi` command which is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. The output of the `nvidia-smi` command is shown in Figure 6. It shows the Driver Version to be 515.86.01 and CUDA version to be 11.7. Figure 5 shows several critical features of the A100 GPU we used. The details of these features are described in Table 1.
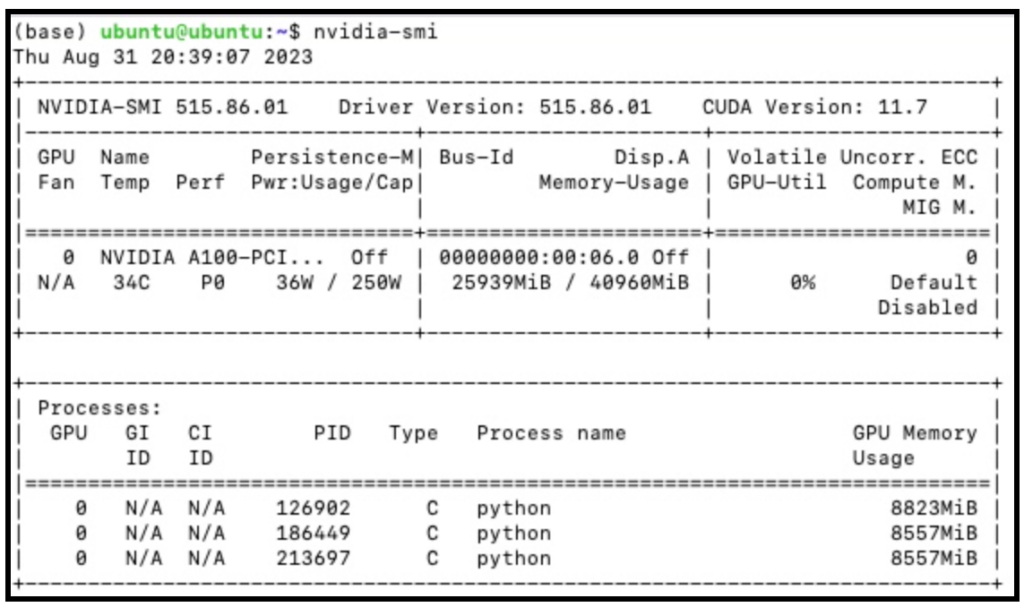
| Feature | Value | Description |
|---|---|---|
| GPU | 0 | GPU Index |
| Name | NVIDIA A100 | GPU Name |
| Temp | 34 C | Core GPU Temperature |
| Perf | P0 | GPU Performance |
| Persistence-M | On | Persistence Mode |
| Pwr: Usage/Cap | 36W / 250W | GPU Power Usage and it capability |
| Bus Id | 00000000:00:06.0 | domain:bus:device.function |
| Disp. A | Off | Display Active |
| Memory-Usage | 25939MiB / 40960MiB | Memory allocation out of total memory |
| Volatile Uncorr. ECC | 0 | Counter of uncorrectable ECC memory error |
| GPU-Util | 0% | GPU Utilization |
| Compute M. | Default | Compute Mode |
| MIG M. | Disabled | Multi-Instance Mode |
Implementation of RLHF Workflow
This section walks through the implementation of the RLHF workflow. We are testing whether the RLHF loop increases the performance of the GPT-2 model by a statistically significant margin.
- Import of Necessary Python Libraries
import torch
from tqdm import tqdm
import pandas as pd
tqdm.pandas()
from transformers import pipeline, AutoTokenizer
from datasets import load_dataset
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
from trl.core import LengthSampler- Set proximal policy optimization (PPO) configurations
config = PPOConfig(
model_name="lvwerra/gpt2-imdb",
learning_rate=1.41e-5,
)
sent_kwargs = {"return_all_scores": True, "function_to_apply": "none", "batch_size": 16}We use “lvwerra/gpt2-imdb” model which is a GPT-2 model fine-tuned on IMDB dataset. The learning rate used us 1.41e-5. Essentially, “lvwerra/gpt2-imdb” is the policy network.
- Build data loader from IMDB dataset
def build_dataset(config, dataset_name="imdb", input_min_text_length=2, input_max_text_length=8):
"""
Build a dataset for training.
Args:
dataset_name (`str`):
The name of the dataset to be loaded.
Returns:
dataloader (`torch.utils.data.DataLoader`):
The data loader for the dataset.
"""
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_token
# load imdb with datasets
ds = load_dataset(dataset_name, split="train")
ds = ds.rename_columns({"text": "review"})
ds = ds.filter(lambda x: len(x["review"]) > 200, batched=False)
input_size = LengthSampler(input_min_text_length, input_max_text_length)
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["review"])[: input_size()]
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
ds = ds.map(tokenize, batched=False)
ds.set_format(type="torch")
return ds- Load Model, Reference Model, and Tokenizer Locally
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_tokenWe use “AutoModelForCausalLMWithValueHead” module from “trl” for the model loading with a value head. We load the model twice: first to optimize with PPO and second to serve as a reference to calculate the KL divergence from the starting point. This serves as a secondary reward signal in the PPO training to make sure the optimized model does not deviate too much from the original language model.
- Initialize PPOTrainer
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator)- Initialize the Reward Model
device = ppo_trainer.accelerator.device
if ppo_trainer.accelerator.num_processes == 1:
device = 0 if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bug
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)For reward model, we use “lvwerra/distilbert-imdb” model which is a fine-tuned version of distilbert-base-uncased. This model assigns a score to the outcome from the policy network. Essentially, it is a proxy of a human evaluator.
- RLHF training loop
At this point, we are ready to run the entire RLHF workflow. We have a GPT-2 based policy network to get the query response, we use BERT to get sentiments for (query, response) pairs, and PPO model to optimize policy with (query, response, reward) triplet. With RLHF, we want to improve the reward score meaning we want to generate responses with more positive sentiments. The following coding block covers the entire training loop:
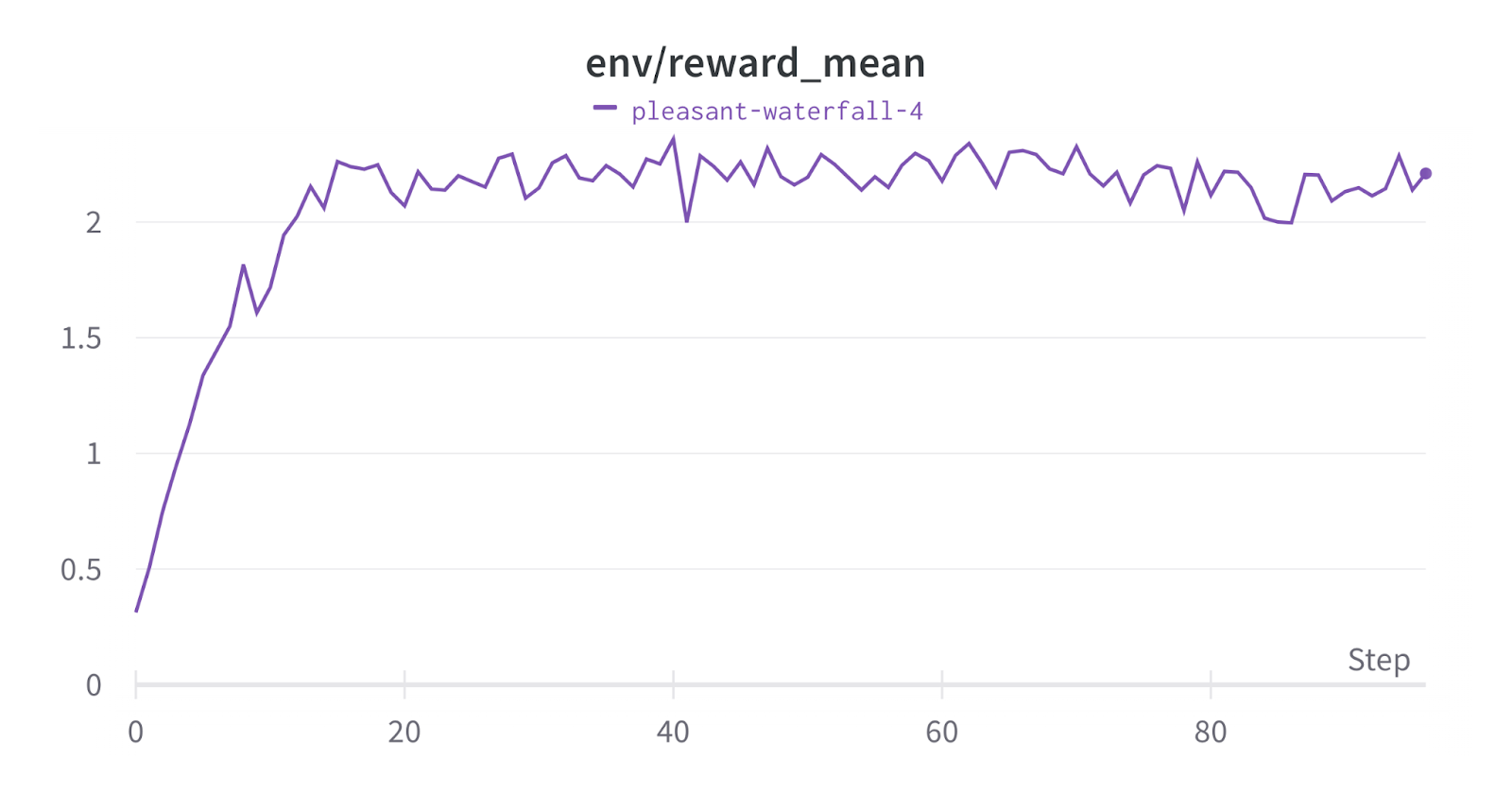
It took nearly 3 hr to run the model on an A100 40GB on the Nutanix infrastructure as it is described previously. During the training we see the model reward keeps increasing and reaches a plateau after ~25 training cycles, as shown in Figure 5.
- RLHF Evaluation
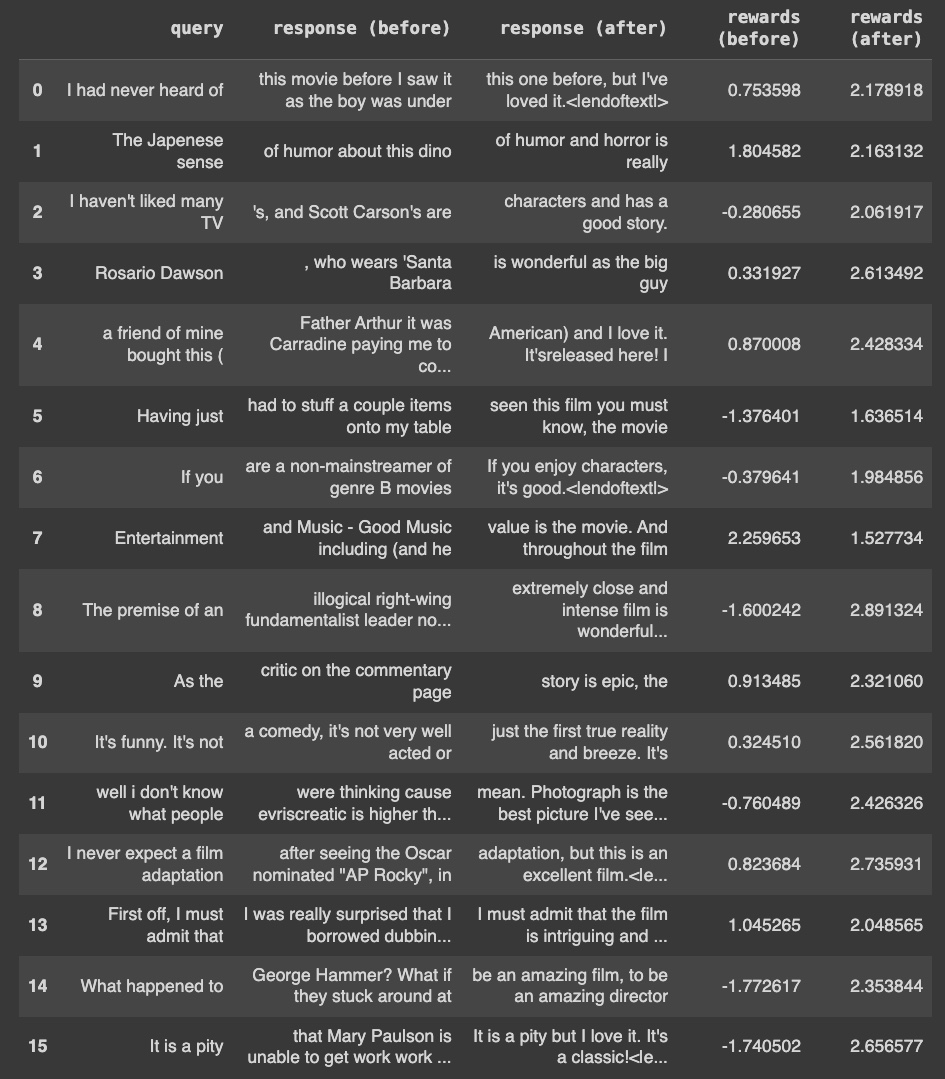
The RLHF loop is evaluated on 15 questions as shown on the following screenshot. As we can see, the PPO based RLHF loop increased the reward 14/15 times. The negative outcome on 7 can be attributed to the sparse one-word query. In aggregate, we see PPO based RLHF training increases the average reward by 30x and the median reward by 7x. It is a significant improvement in the reward score, validating the effectiveness of RLHF in LLM adaptation.
Key Takeaways
- We trained an RLHF loop end-to-end from scratch with PPO algorithm with IMDB movie database.
- The trained RLHF shows significant improvement on reward score meaning it is successful in LLM behavior adaptation.
- Finally, it is worth mentioning that in this article, we replace direct human feedback with a Bert based reward network.
© 2023 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.
This post may contain express and implied forward-looking statements, which are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances