

Summary
Large Language Models (LLMs), based on the transformer architecture, like GPT, T5, and BERT, have achieved state-of-the-art (SOTA) results in various Natural Language Processing (NLP) tasks especially for text generation and conversational bots. The conventional paradigm is large-scale pretraining on generic web-scale data (CommonCrawl), followed by fine-tuning to downstream tasks. Fine-tuning these pretrained LLMs on downstream datasets results in huge performance gains for the specific downstream tasks when compared to using the pretrained LLMs out-of-the-box (zero-shot inference, for example). However, as LLMs get larger in parameter counts and training token counts, full fine-tuning becomes challenging computationally. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because full-scale fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches, such as LoRA, KronA, LeTS, address these problems around computing and storage. The fundamental idea of PEFT is to train on a small portion of the model parameters for a fine-tuning dataset while keeping the remaining fixed, thereby greatly decreasing the computational and storage costs. This also overcomes the issues of catastrophic forgetting, a behavior observed during the full finetuning of LLMs. In this article, we present how a pertained LLM can be finetuned using PEFT on Nutanix Cloud Platform (NCP) which is optimized for easy manageability and resiliency with the state-of-the-art AI infrastructure including high-performance GPU, fast NVMe, and storage scaling.
Pre-Training–Fine-Tuning Paradigm
LLM Pre-training typically involves heavily over-parameterized transformers as the base architecture and model natural language in bidirectional, autoregressive, or sequence-to-sequence manners on large-scale unsupervised corpora. Then for downstream tasks, task-specific objectives are introduced to fine-tune the pre-trained LLM for model adaptation. Notably, the increasing scale of pre-trained LLMs (measured by the number of parameters) seems to be inevitable, as constant empirical results show that larger models (along with more data) almost certainly lead to better performance. For example, with 175 billion parameters, Generative Pre-trained Transformer (GPT-3) generates natural language of unprecedented quality and can conduct various desired zero-shot tasks with satisfactory results given appropriate prompts. Subsequently, a series of large-scale models such as Gopher, Megatron-Turing Natural Language Generation (NLG), and Pathways Language Model (PaLM) have repeatedly shown effectiveness on a broad range of downstream tasks. Although in-context learning has shown promising performance for pre-trained LLMs such as GPT-3, fine-tuning still overtakes it under the task-specific setting. However, the predominant approach, full parameter fine-tuning, which initializes the model with the pre-trained weights, updates all the parameters and produces separate instances for different tasks, becomes untenable when dealing with large-scale models. In addition to the cost of deployment and computation, storing different instances for different tasks is extremely memory intensive.
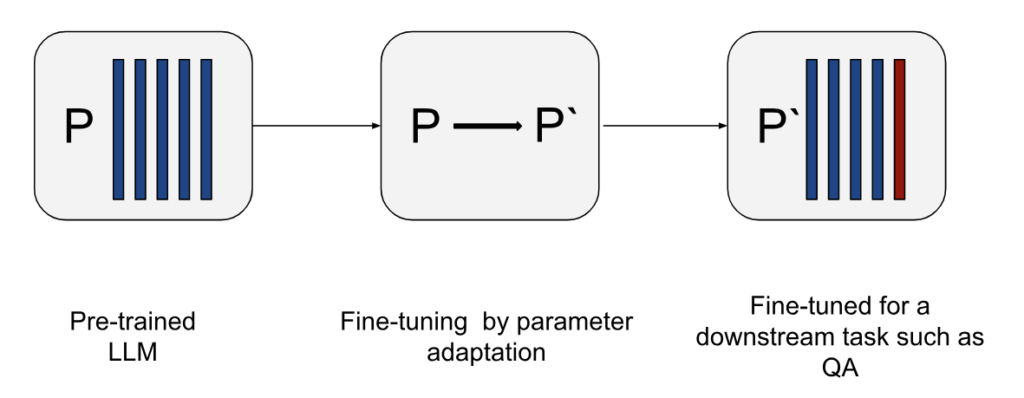
Figure 1 shows a schematic representation for the pre-training-fine-tuning paradigm. In this context, PEFT optimizes fine-tuning transformation (P → P`).
Categories of PEFT Methods
PEFT methods can be classified in multiple ways. They may be differentiated by their underlying approach or conceptual framework: does the method introduce new parameters to the model, or does it fine-tune a small subset of existing parameters? Alternatively, they may be categorized according to their primary objective: does the method aim to minimize memory footprint or only storage efficiency? There are different PEFT categories, as follows:
- Additive Method: The idea behind additive methods is augmenting the existing pre-trained model with extra parameters or layers and training only the newly added parameters. Although these methods introduce additional parameters to the network, they improve training time and space efficiency by reducing the size of the gradient and the optimizer states. This is the largest and widely explored PEFT methods including two sub-categories such as Adapter and Soft Prompts.
- Adapters: Adapters involve the introduction of small fully-connected networks after Transformer sub-layers. A few examples of adapters are AdaMix, KronA, Compactor.
- Soft Prompts: In this method, a part of the model’s input embeddings is fine-tuned via gradient descent. IPT, prefix-tuning, and WARP are a few prominent examples of soft prompts.
- Other Additive Approaches: LeTS, AttentionFusion, Ladder-Side Tuning are examples of other additive approaches.
- Selective Method: Selective PEFTs only finetunes a few top layers. The selection is based on the layer type and model internal structure, such as tuning only model biases or only particular rows. Examples of selective PEFT are BitFit, LN tuning.
- Reparametrization-based Method: Reparametrization-based PEFT methods leverage low-rank representations to minimize the number of trainable parameters. The deep learning literature has demonstrated that fine-tuning can be performed effectively in low-rank subspaces. Most well-known reparametrization-based method is Low-Rank Adaptation or LoRA which employs a simple low-rank matrix decomposition to parametrize the weight update. In this article, we demonstrate how to use LoRA as a PEFT method for a LLM fine-tuning task on Nutanix Cloud Platform.
Low Rank Parameter Adaptation (LoRA)
A neural network contains many dense layers which perform matrix multiplication.The weight matrices in these layers typically have full-rank. The literature shows that the pre-trained language models have a low “intrinsic dimension” and can still learn efficiently despite a random projection to a smaller subspace. LoRA is based on this hypothesis that the updates to the weights also have a low “intrinsic rank” during adaptation. For a pre-trained weight matrix W0 ∈ Rd×k , (d is the number of rows and k is the number of columns of W0) we constrain its update by representing the latter with low-rank decomposition, ∆W=W0+BA, where B∈ Rd×r, A∈Rr×k, and the rank r << min(d,k). During training, W0 is frozen and does not receive gradient updates, while A and B contain trainable parameters. Figure 2 shows a forward pass for LoRA as presented in Equation (1).
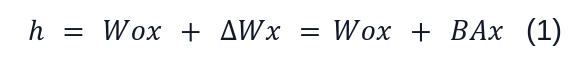
We use a random Gaussian initialization for A and zero for B, so ΔW=BA remains zero at the beginning of the training. We then scale ΔWx by r, where is a constant in r. When optimizing with Adam, tuning is roughly the same as tuning learning rate if we scale the initialization appropriately.

Demonstration of Model Fine-tuning using PEFT
Nutanix Infrastructure
At Nutanix, we are dedicated to enabling customers with the ability to build and deploy intelligent applications anywhere—edge, core data centers, service provider infrastructure, and public clouds. Prism Element (PE) is a service built into the platform for every Nutanix cluster deployed. Prism Element enables a user to fully configure, manage, and monitor Nutanix clusters running any hypervisor. Therefore, the first step of the Nutanix infrastructure setup is to log into a Prism Element, as Shown in Figure 3.
- Log into Prism Element on a Cluster (UI shown in Figure 3)

- Set up the VM
After logging into Prism Element1, we create a VM hosted on our Nutanix AHV cluster. As shown in Figure 4, the VM has following resource configuration settings: 22.04 Ubuntu operating system, 16 single core vCPUs, 64 GB of RAM, and NVIDIA A100 tensor core passthrough GPU with 80GB memory. The GPU is installed with the NVIDIA RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run). The large deep learning models with transformer architecture require GPU or other compute accelerators with high memory bandwidth, large registers and L1 memory.

- Underlying A100 GPU
NVIDIA A100 Tensor Core GPU is designed to power the world’s highest-performing elastic data centers for AI, data analytics, and HPC. Powered by the NVIDIA Ampere Architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands. To peek into the detailed features of A100 GPU, we run `nvidia-smi` command which is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. The output of the `nvidia-smi` command is shown in Figure 5. It shows the Driver Version to be 525.60.13 and CUDA version to be 12.0.

Table 1 shows several key features of the A100 GPU we used. The details of these features are described in Table 2.
| Feature | Value | Description |
|---|---|---|
| GPU | 0 | GPU Index |
| Name | NVIDIA A100 | GPU Name |
| Temp | 36 C | Core GPU Temperature |
| Perf | P0 | GPU Performance |
| Persistence-M | On | Persistence Mode |
| Pwr: Usage/Cap | 65 W / 300 W | GPU Power Usage and it capability |
| Bus Id | 00000000:00:06.0 | domain:bus:device.function |
| Disp. A | Off | Display Active |
| Memory-Usage | 44136MiB / 81920MiB | Memory allocation out of total memory |
| Volatile Uncorr. ECC | 0 | Counter of uncorrectable ECC memory error |
| GPU-Util | 0% | GPU Utilization |
| Compute M. | Default | Compute Mode |
| MIG M. | Disabled | Multi-Instance Mode |
Computational Steps
Let’s consider the case of fine-tuning the model, bigscience/mt0-large, using LoRA. The model is available with apache2.0 license on Hugging Face Hub. The fine-tuning involves following key steps:
- Bring the necessary imports
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
# os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
checkpoint_name = "financial_sentiment_analysis_lora_v1.pt"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 1e-3
num_epochs = 3
batch_size = 8- Creating config corresponding to the PEFT method and model setup
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)LoraConfig is an important dataclass from PeftConfig. The detailed codebase for PeftConfig is available at https://github.com/huggingface/peft. The arguments for this dataclass is described in the following table, Table 1:
| Argument (type, default) | Description |
|---|---|
| r (`int`, 8) | Lora attention dimension. |
| target_modules (`Union[List[str], str]`, None) | The names of the modules to apply Lora to |
| lora_alpha (`int`, 8) | The alpha parameter for Lora scaling |
| lora_dropout (`float`, 0.0) | The dropout probability for Lora layers |
| fan_in_fan_out (`boolean`, False) | Set this to True if the layer to replace stores weight like (fan_in, fan_out) |
| bias (`str`, “none”) | Bias type for Lora. Can be ‘none’, ‘all’ or ‘lora_only’ |
| modules_to_save (`List[str]`, None) | List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint |
| Layers_to_transform (`Union[List[int], int]`, None) | The layer indexes to transform, if this argument is specified, it will apply the LoRA transformations on the layer indexes that are specified in this list. If a single integer is passed, it will apply the LoRA transformations on the layer at this index. |
| layers_pattern (`str`, None) | The layer pattern name, used only if `layers_to_transform` is different from `None` and if the layer pattern is not in the common layers pattern. |
- Wrapping base model by calling get_peft_model
An example of the measure of the parameter efficiency is shown below. This code block outputs the trainable parameter and total parameter counts. It shows the PEFT finetunes only 0.19% of parameters ( ~2M out of 1B parameters).
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()trainable params: 2,359,296 || all params: 1,231,940,608 || trainable%: 0.19151053100118282- Model Saving
peft_model_id =f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)This will only save the incremental PEFT weights that were trained. For example, we train bigscience/mt0-large model with financial_phasebank dataset. The model file just produces two files: adapter_config.json and adapter_model.bin with the latter being just 9.2MB.

Conclusion
In this article, we show how Nutanix Cloud Platform (NCP) can be used for performing PEFT which is an efficient way of tuning large LLMs on downstream tasks and domains, saving significant compute and storage while achieving comparable performance to full finetuning. In general, PEFT takes about 1 hour on a high-end NVIDIA A100 GPU and 10-100MB of storage, depending on the instruction-tuning dataset and the foundation model complexity.
This is our third article in our AI article series. The previous two articles cover how Nutanix Cloud Platform can be leveraged to implement attention mechanism and build a transformer model from scratch, respectively.
Footnotes
- A third-party user would need to interface with Prism Central to log into Prism Element running on a cluster with an appropriate role-based access control (RBAC) credential.